Complete Results
These results are based on Stanley (2017) data-generating mechanism with a total of 324 conditions.
Average Performance
Method performance measures are aggregated across all simulated conditions to provide an overall impression of method performance. However, keep in mind that a method with a high overall ranking is not necessarily the “best” method for a particular application. To select a suitable method for your application, consider also non-aggregated performance measures in conditions most relevant to your application.
| Rank | Method | Mean Rank | Rank | Method | Mean Rank |
|---|---|---|---|---|---|
| 1 | RoBMA (PSMA) | 5.090 | 1 | RoBMA (PSMA) | 5.441 |
| 2 | AK (AK1) | 7.287 | 2 | AK (AK1) | 7.231 |
| 3 | SM (3PSM) | 7.599 | 3 | SM (3PSM) | 7.512 |
| 4 | FMA (default) | 8.858 | 4 | FMA (default) | 8.864 |
| 5 | WLS (default) | 8.870 | 5 | WLS (default) | 8.877 |
| 6 | WAAPWLS (default) | 8.960 | 6 | WAAPWLS (default) | 9.015 |
| 7 | SM (4PSM) | 10.003 | 7 | SM (4PSM) | 9.972 |
| 8 | puniform (star) | 10.049 | 8 | puniform (star) | 10.000 |
| 9 | WILS (default) | 10.176 | 9 | WILS (default) | 10.114 |
| 10 | RMA (default) | 10.769 | 10 | RMA (default) | 10.787 |
| 11 | trimfill (default) | 10.787 | 11 | trimfill (default) | 10.815 |
| 12 | PETPEESE (default) | 10.926 | 12 | PETPEESE (default) | 10.923 |
| 13 | PEESE (default) | 10.938 | 13 | PEESE (default) | 10.969 |
| 14 | EK (default) | 12.136 | 14 | EK (default) | 12.127 |
| 15 | PET (default) | 12.198 | 15 | PET (default) | 12.188 |
| 16 | AK (AK2) | 12.451 | 16 | AK (AK2) | 12.247 |
| 17 | MAIVE (default) | 12.775 | 17 | MAIVE (default) | 12.772 |
| 18 | pcurve (default) | 13.719 | 18 | pcurve (default) | 13.728 |
| 19 | puniform (default) | 14.383 | 19 | puniform (default) | 14.358 |
| 20 | mean (default) | 14.846 | 20 | mean (default) | 14.895 |
| 21 | MAIVE (WAIVE) | 15.590 | 21 | MAIVE (WAIVE) | 15.571 |
RMSE (Root Mean Square Error) is an overall summary measure of estimation performance that combines bias and empirical SE. RMSE is the square root of the average squared difference between the meta-analytic estimate and the true effect across simulation runs. A lower RMSE indicates a better method. Methods are compared using condition-wise ranks. Direct comparison using the average RMSE is not possible because the data-generating mechanisms differ in the outcome scale. See the DGM-specific results (or subresults) to see the distribution of RMSE values on the corresponding outcome scale.
| Rank | Method | Mean Rank | Rank | Method | Mean Rank |
|---|---|---|---|---|---|
| 1 | SM (3PSM) | 7.235 | 1 | SM (3PSM) | 7.191 |
| 2 | SM (4PSM) | 7.617 | 2 | SM (4PSM) | 7.676 |
| 3 | RoBMA (PSMA) | 8.281 | 3 | RoBMA (PSMA) | 8.491 |
| 4 | AK (AK1) | 8.556 | 4 | AK (AK1) | 8.577 |
| 5 | MAIVE (default) | 9.262 | 5 | puniform (star) | 9.250 |
| 6 | puniform (star) | 9.265 | 6 | MAIVE (default) | 9.275 |
| 7 | PETPEESE (default) | 9.651 | 7 | PETPEESE (default) | 9.685 |
| 8 | EK (default) | 9.830 | 8 | EK (default) | 9.843 |
| 9 | PET (default) | 9.840 | 9 | PET (default) | 9.852 |
| 10 | WAAPWLS (default) | 10.191 | 10 | WAAPWLS (default) | 10.287 |
| 11 | PEESE (default) | 10.602 | 11 | PEESE (default) | 10.654 |
| 12 | WLS (default) | 11.228 | 12 | WLS (default) | 11.330 |
| 13 | FMA (default) | 11.244 | 13 | FMA (default) | 11.346 |
| 14 | MAIVE (WAIVE) | 11.873 | 14 | AK (AK2) | 11.698 |
| 15 | WILS (default) | 12.299 | 15 | MAIVE (WAIVE) | 11.843 |
| 16 | AK (AK2) | 12.546 | 16 | WILS (default) | 12.302 |
| 17 | RMA (default) | 13.025 | 17 | RMA (default) | 13.052 |
| 18 | puniform (default) | 13.154 | 18 | puniform (default) | 13.160 |
| 19 | trimfill (default) | 13.515 | 19 | trimfill (default) | 13.596 |
| 20 | pcurve (default) | 14.096 | 20 | pcurve (default) | 14.130 |
| 21 | mean (default) | 15.423 | 21 | mean (default) | 15.497 |
Bias is the average difference between the meta-analytic estimate and the true effect across simulation runs. Ideally, this value should be close to 0. Methods are compared using condition-wise ranks. Direct comparison using the average bias is not possible because the data-generating mechanisms differ in the outcome scale. See the DGM-specific results (or subresults) to see the distribution of bias values on the corresponding outcome scale.
| Rank | Method | Mean Rank | Rank | Method | Mean Rank |
|---|---|---|---|---|---|
| 1 | RMA (default) | 3.380 | 1 | RMA (default) | 3.238 |
| 2 | WLS (default) | 3.975 | 2 | WLS (default) | 3.821 |
| 3 | FMA (default) | 3.981 | 3 | FMA (default) | 3.827 |
| 4 | AK (AK1) | 5.781 | 4 | AK (AK1) | 5.920 |
| 5 | WAAPWLS (default) | 7.262 | 5 | WAAPWLS (default) | 7.188 |
| 6 | trimfill (default) | 7.509 | 6 | trimfill (default) | 7.466 |
| 7 | RoBMA (PSMA) | 7.796 | 7 | RoBMA (PSMA) | 8.148 |
| 8 | mean (default) | 8.238 | 8 | mean (default) | 8.160 |
| 9 | SM (3PSM) | 10.090 | 9 | SM (3PSM) | 10.080 |
| 10 | PEESE (default) | 11.481 | 10 | PEESE (default) | 11.475 |
| 11 | pcurve (default) | 11.642 | 11 | pcurve (default) | 11.562 |
| 12 | WILS (default) | 11.870 | 12 | WILS (default) | 11.855 |
| 13 | puniform (default) | 12.515 | 13 | puniform (default) | 12.460 |
| 14 | puniform (star) | 12.528 | 14 | puniform (star) | 12.531 |
| 15 | AK (AK2) | 13.654 | 15 | SM (4PSM) | 14.052 |
| 16 | SM (4PSM) | 14.099 | 16 | AK (AK2) | 14.062 |
| 17 | PETPEESE (default) | 14.491 | 17 | PETPEESE (default) | 14.506 |
| 18 | MAIVE (default) | 15.756 | 18 | MAIVE (default) | 15.762 |
| 19 | EK (default) | 16.503 | 19 | EK (default) | 16.478 |
| 20 | PET (default) | 16.552 | 20 | PET (default) | 16.531 |
| 21 | MAIVE (WAIVE) | 19.410 | 21 | MAIVE (WAIVE) | 19.392 |
The empirical SE is the standard deviation of the meta-analytic estimate across simulation runs. A lower empirical SE indicates less variability and better method performance. Methods are compared using condition-wise ranks. Direct comparison using the average empirical standard error is not possible because the data-generating mechanisms differ in the outcome scale. See the DGM-specific results (or subresults) to see the distribution of empirical standard error values on the corresponding outcome scale.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | RoBMA (PSMA) | 4.154 | 1 | RoBMA (PSMA) | 4.494 |
| 2 | SM (3PSM) | 5.787 | 2 | SM (3PSM) | 5.917 |
| 3 | puniform (star) | 6.540 | 3 | puniform (star) | 6.577 |
| 4 | AK (AK1) | 7.012 | 4 | AK (AK1) | 6.954 |
| 5 | SM (4PSM) | 7.840 | 5 | SM (4PSM) | 7.506 |
| 6 | WAAPWLS (default) | 9.985 | 6 | WAAPWLS (default) | 10.130 |
| 7 | MAIVE (default) | 10.602 | 7 | EK (default) | 10.559 |
| 8 | EK (default) | 10.608 | 8 | MAIVE (default) | 10.577 |
| 9 | WLS (default) | 10.725 | 9 | RMA (default) | 10.775 |
| 10 | RMA (default) | 10.753 | 10 | WLS (default) | 10.781 |
| 11 | trimfill (default) | 11.235 | 11 | AK (AK2) | 11.287 |
| 12 | PETPEESE (default) | 11.383 | 12 | trimfill (default) | 11.302 |
| 13 | PEESE (default) | 11.438 | 13 | PETPEESE (default) | 11.386 |
| 14 | AK (AK2) | 11.583 | 14 | PEESE (default) | 11.500 |
| 15 | PET (default) | 11.784 | 15 | PET (default) | 11.725 |
| 16 | puniform (default) | 12.938 | 16 | WILS (default) | 12.941 |
| 17 | WILS (default) | 13.000 | 17 | puniform (default) | 12.954 |
| 18 | MAIVE (WAIVE) | 13.086 | 18 | MAIVE (WAIVE) | 13.028 |
| 19 | FMA (default) | 13.256 | 19 | FMA (default) | 13.265 |
| 20 | mean (default) | 15.719 | 20 | mean (default) | 15.772 |
| 21 | pcurve (default) | 21.000 | 21 | pcurve (default) | 21.000 |
The interval score measures the accuracy of a confidence interval by combining its width and coverage. It penalizes intervals that are too wide or that fail to include the true value. A lower interval score indicates a better method. Methods are compared using condition-wise ranks. Direct comparison using the average Interval Score is not possible because the data-generating mechanisms differ in the outcome scale. See the DGM-specific results (or subresults) to see the distribution of empirical standard error values on the corresponding outcome scale.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | RoBMA (PSMA) | 0.902 | 1 | RoBMA (PSMA) | 0.896 |
| 2 | SM (4PSM) | 0.845 | 2 | SM (4PSM) | 0.833 |
| 3 | AK (AK2) | 0.801 | 3 | MAIVE (default) | 0.796 |
| 4 | MAIVE (default) | 0.796 | 4 | AK (AK2) | 0.783 |
| 5 | puniform (star) | 0.765 | 5 | puniform (star) | 0.765 |
| 6 | SM (3PSM) | 0.743 | 6 | MAIVE (WAIVE) | 0.737 |
| 7 | MAIVE (WAIVE) | 0.737 | 7 | SM (3PSM) | 0.736 |
| 8 | EK (default) | 0.715 | 8 | EK (default) | 0.715 |
| 9 | PET (default) | 0.688 | 9 | PET (default) | 0.688 |
| 10 | PETPEESE (default) | 0.681 | 10 | PETPEESE (default) | 0.681 |
| 11 | AK (AK1) | 0.608 | 11 | AK (AK1) | 0.607 |
| 12 | puniform (default) | 0.541 | 12 | puniform (default) | 0.542 |
| 13 | PEESE (default) | 0.524 | 13 | PEESE (default) | 0.524 |
| 14 | WAAPWLS (default) | 0.510 | 14 | WAAPWLS (default) | 0.510 |
| 15 | trimfill (default) | 0.497 | 15 | trimfill (default) | 0.497 |
| 16 | WILS (default) | 0.494 | 16 | WILS (default) | 0.494 |
| 17 | RMA (default) | 0.493 | 17 | RMA (default) | 0.493 |
| 18 | WLS (default) | 0.481 | 18 | WLS (default) | 0.481 |
| 19 | FMA (default) | 0.380 | 19 | FMA (default) | 0.380 |
| 20 | mean (default) | 0.366 | 20 | mean (default) | 0.366 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
95% CI coverage is the proportion of simulation runs in which the 95% confidence interval contained the true effect. Ideally, this value should be close to the nominal level of 95%.
| Rank | Method | Mean Rank | Rank | Method | Mean Rank |
|---|---|---|---|---|---|
| 1 | FMA (default) | 2.373 | 1 | FMA (default) | 2.346 |
| 2 | WILS (default) | 3.188 | 2 | WILS (default) | 3.139 |
| 3 | WLS (default) | 3.969 | 3 | WLS (default) | 3.904 |
| 4 | WAAPWLS (default) | 5.972 | 4 | WAAPWLS (default) | 5.883 |
| 5 | trimfill (default) | 7.105 | 5 | trimfill (default) | 7.015 |
| 6 | RMA (default) | 7.148 | 6 | RMA (default) | 7.049 |
| 7 | mean (default) | 8.540 | 7 | mean (default) | 8.537 |
| 8 | PEESE (default) | 9.074 | 8 | PEESE (default) | 9.096 |
| 9 | RoBMA (PSMA) | 9.204 | 9 | RoBMA (PSMA) | 9.198 |
| 10 | AK (AK1) | 9.336 | 10 | AK (AK1) | 9.340 |
| 11 | SM (3PSM) | 10.833 | 11 | SM (3PSM) | 10.904 |
| 12 | PETPEESE (default) | 11.491 | 12 | PETPEESE (default) | 11.537 |
| 13 | puniform (default) | 11.923 | 13 | puniform (default) | 11.886 |
| 14 | puniform (star) | 12.753 | 14 | puniform (star) | 12.932 |
| 15 | AK (AK2) | 14.386 | 15 | SM (4PSM) | 14.410 |
| 16 | SM (4PSM) | 14.639 | 16 | AK (AK2) | 14.503 |
| 17 | PET (default) | 15.330 | 17 | PET (default) | 15.395 |
| 18 | EK (default) | 16.812 | 18 | EK (default) | 16.895 |
| 19 | MAIVE (default) | 16.898 | 19 | MAIVE (default) | 16.975 |
| 20 | MAIVE (WAIVE) | 18.454 | 20 | MAIVE (WAIVE) | 18.485 |
| 21 | pcurve (default) | 21.000 | 21 | pcurve (default) | 21.000 |
95% CI width is the average length of the 95% confidence interval for the true effect. A lower average 95% CI length indicates a better method. Methods are compared using condition-wise ranks. Direct comparison using the average CI width is not possible because the data-generating mechanisms differ in the outcome scale. See the DGM-specific results (or subresults) to see the distribution of CI width values on the corresponding outcome scale.
| Rank | Method | Log Value | Rank | Method | Log Value |
|---|---|---|---|---|---|
| 1 | RoBMA (PSMA) | 5.355 | 1 | RoBMA (PSMA) | 4.807 |
| 2 | AK (AK2) | 2.939 | 2 | AK (AK2) | 2.293 |
| 3 | SM (4PSM) | 2.219 | 3 | SM (4PSM) | 2.238 |
| 4 | puniform (star) | 2.163 | 4 | puniform (star) | 2.163 |
| 5 | MAIVE (WAIVE) | 2.146 | 5 | MAIVE (WAIVE) | 2.146 |
| 6 | SM (3PSM) | 1.998 | 6 | SM (3PSM) | 1.984 |
| 7 | MAIVE (default) | 1.956 | 7 | MAIVE (default) | 1.956 |
| 8 | EK (default) | 1.840 | 8 | EK (default) | 1.840 |
| 9 | PET (default) | 1.838 | 9 | PET (default) | 1.838 |
| 10 | PETPEESE (default) | 1.834 | 10 | PETPEESE (default) | 1.834 |
| 11 | puniform (default) | 1.728 | 11 | puniform (default) | 1.667 |
| 12 | AK (AK1) | 1.493 | 12 | AK (AK1) | 1.445 |
| 13 | WILS (default) | 1.370 | 13 | WILS (default) | 1.370 |
| 14 | RMA (default) | 1.161 | 14 | RMA (default) | 1.161 |
| 15 | PEESE (default) | 1.109 | 15 | PEESE (default) | 1.109 |
| 16 | WAAPWLS (default) | 1.056 | 16 | WAAPWLS (default) | 1.056 |
| 17 | WLS (default) | 1.019 | 17 | WLS (default) | 1.019 |
| 18 | trimfill (default) | 0.953 | 18 | trimfill (default) | 0.953 |
| 19 | mean (default) | 0.849 | 19 | mean (default) | 0.849 |
| 20 | FMA (default) | 0.800 | 20 | FMA (default) | 0.800 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
The positive likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a positive likelihood ratio greater than 1 (or a log positive likelihood ratio greater than 0). A higher (log) positive likelihood ratio indicates a better method.
| Rank | Method | Log Value | Rank | Method | Log Value |
|---|---|---|---|---|---|
| 1 | SM (3PSM) | -4.898 | 1 | AK (AK2) | -6.215 |
| 2 | RoBMA (PSMA) | -4.722 | 2 | SM (3PSM) | -4.947 |
| 3 | PETPEESE (default) | -4.721 | 3 | SM (4PSM) | -4.828 |
| 4 | AK (AK2) | -4.622 | 4 | RoBMA (PSMA) | -4.737 |
| 5 | EK (default) | -4.570 | 5 | PETPEESE (default) | -4.721 |
| 6 | PET (default) | -4.570 | 6 | EK (default) | -4.570 |
| 7 | SM (4PSM) | -4.438 | 7 | PET (default) | -4.570 |
| 8 | MAIVE (default) | -4.415 | 8 | MAIVE (default) | -4.415 |
| 9 | puniform (star) | -4.287 | 9 | puniform (star) | -4.287 |
| 10 | PEESE (default) | -3.817 | 10 | PEESE (default) | -3.817 |
| 11 | WILS (default) | -3.661 | 11 | WILS (default) | -3.661 |
| 12 | puniform (default) | -3.597 | 12 | puniform (default) | -3.603 |
| 13 | trimfill (default) | -3.502 | 13 | trimfill (default) | -3.502 |
| 14 | AK (AK1) | -3.458 | 14 | AK (AK1) | -3.461 |
| 15 | WLS (default) | -3.393 | 15 | WLS (default) | -3.393 |
| 16 | RMA (default) | -3.312 | 16 | RMA (default) | -3.312 |
| 17 | FMA (default) | -3.220 | 17 | FMA (default) | -3.220 |
| 18 | WAAPWLS (default) | -3.095 | 18 | WAAPWLS (default) | -3.095 |
| 19 | mean (default) | -2.700 | 19 | mean (default) | -2.700 |
| 20 | MAIVE (WAIVE) | -2.422 | 20 | MAIVE (WAIVE) | -2.422 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
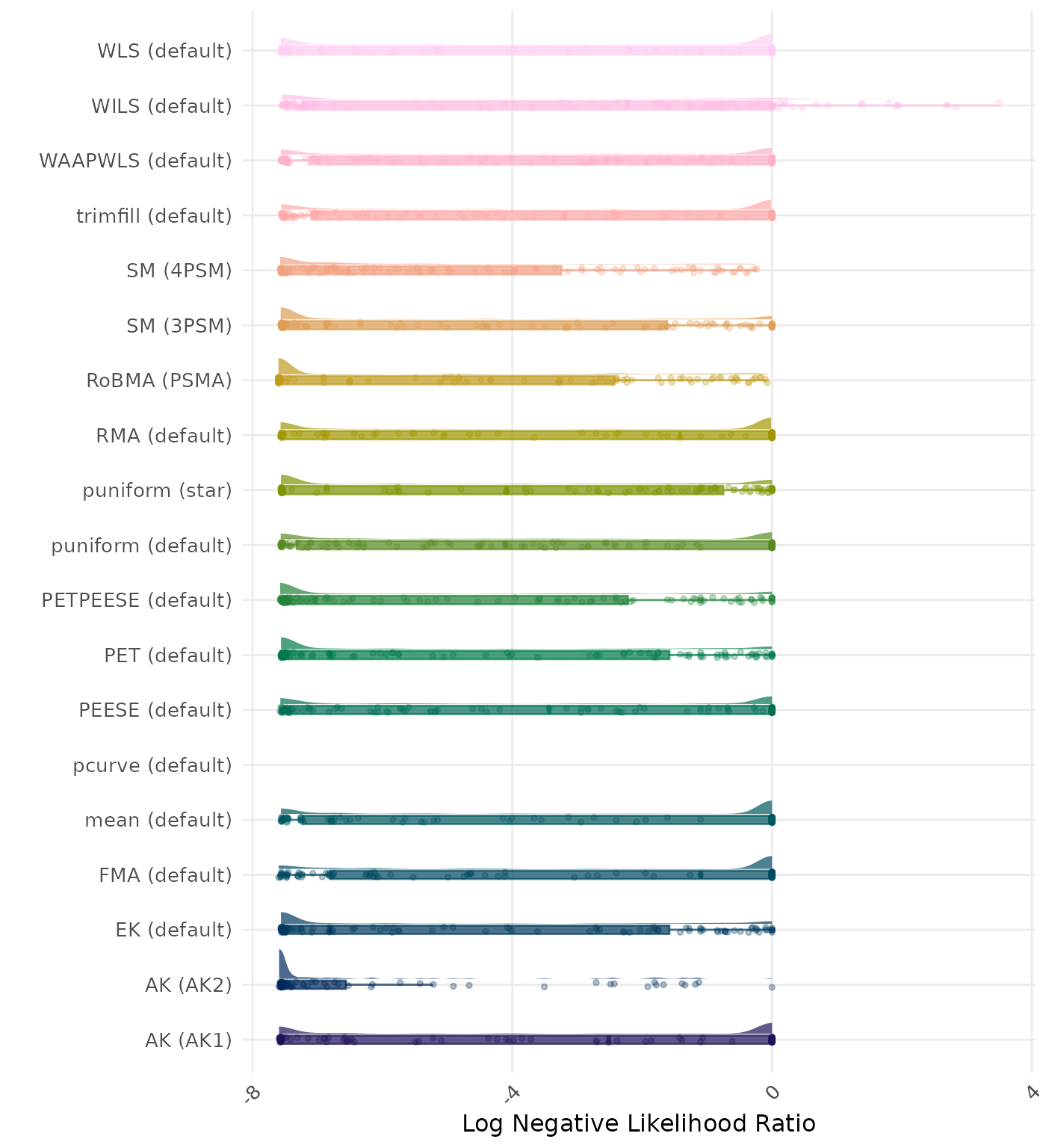
The negative likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a non-significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a negative likelihood ratio less than 1 (or a log negative likelihood ratio less than 0). A lower (log) negative likelihood ratio indicates a better method.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | RoBMA (PSMA) | 0.022 | 1 | RoBMA (PSMA) | 0.031 |
| 2 | AK (AK2) | 0.082 | 2 | MAIVE (WAIVE) | 0.112 |
| 3 | MAIVE (WAIVE) | 0.112 | 3 | SM (4PSM) | 0.125 |
| 4 | SM (4PSM) | 0.112 | 4 | AK (AK2) | 0.156 |
| 5 | PET (default) | 0.237 | 5 | PET (default) | 0.237 |
| 6 | EK (default) | 0.237 | 6 | EK (default) | 0.237 |
| 7 | MAIVE (default) | 0.238 | 7 | MAIVE (default) | 0.238 |
| 8 | puniform (star) | 0.242 | 8 | puniform (star) | 0.242 |
| 9 | PETPEESE (default) | 0.269 | 9 | PETPEESE (default) | 0.269 |
| 10 | SM (3PSM) | 0.282 | 10 | SM (3PSM) | 0.288 |
| 11 | WILS (default) | 0.373 | 11 | WILS (default) | 0.373 |
| 12 | PEESE (default) | 0.541 | 12 | PEESE (default) | 0.541 |
| 13 | puniform (default) | 0.544 | 13 | puniform (default) | 0.542 |
| 14 | AK (AK1) | 0.556 | 14 | AK (AK1) | 0.557 |
| 15 | WAAPWLS (default) | 0.573 | 15 | WAAPWLS (default) | 0.573 |
| 16 | RMA (default) | 0.603 | 16 | RMA (default) | 0.603 |
| 17 | WLS (default) | 0.612 | 17 | WLS (default) | 0.612 |
| 18 | trimfill (default) | 0.615 | 18 | trimfill (default) | 0.615 |
| 19 | mean (default) | 0.688 | 19 | mean (default) | 0.688 |
| 20 | FMA (default) | 0.720 | 20 | FMA (default) | 0.720 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
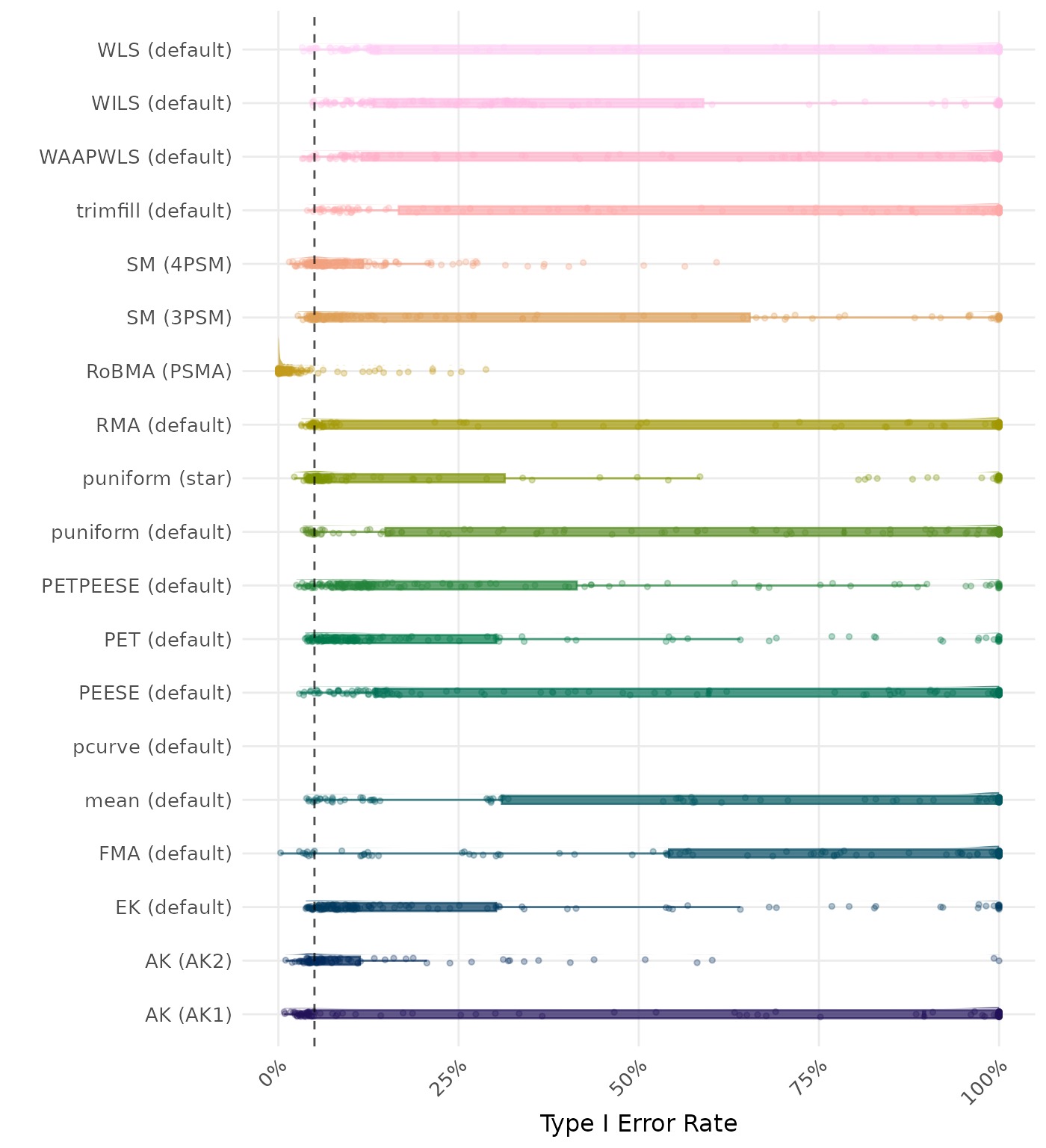
The type I error rate is the proportion of simulation runs in which the null hypothesis of no effect was incorrectly rejected when it was true. Ideally, this value should be close to the nominal level of 5%.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | FMA (default) | 0.990 | 1 | FMA (default) | 0.990 |
| 2 | WLS (default) | 0.981 | 2 | WLS (default) | 0.981 |
| 3 | RMA (default) | 0.980 | 3 | RMA (default) | 0.980 |
| 4 | trimfill (default) | 0.979 | 4 | trimfill (default) | 0.979 |
| 5 | AK (AK1) | 0.970 | 5 | AK (AK2) | 0.977 |
| 6 | mean (default) | 0.965 | 6 | AK (AK1) | 0.970 |
| 7 | WAAPWLS (default) | 0.956 | 7 | mean (default) | 0.965 |
| 8 | PEESE (default) | 0.951 | 8 | WAAPWLS (default) | 0.956 |
| 9 | AK (AK2) | 0.949 | 9 | PEESE (default) | 0.951 |
| 10 | SM (3PSM) | 0.936 | 10 | SM (3PSM) | 0.945 |
| 11 | puniform (default) | 0.911 | 11 | puniform (default) | 0.913 |
| 12 | WILS (default) | 0.898 | 12 | SM (4PSM) | 0.900 |
| 13 | PETPEESE (default) | 0.884 | 13 | WILS (default) | 0.898 |
| 14 | puniform (star) | 0.876 | 14 | PETPEESE (default) | 0.884 |
| 15 | SM (4PSM) | 0.869 | 15 | puniform (star) | 0.876 |
| 16 | MAIVE (default) | 0.866 | 16 | MAIVE (default) | 0.866 |
| 17 | EK (default) | 0.852 | 17 | EK (default) | 0.852 |
| 18 | PET (default) | 0.851 | 18 | PET (default) | 0.851 |
| 19 | RoBMA (PSMA) | 0.832 | 19 | RoBMA (PSMA) | 0.834 |
| 20 | MAIVE (WAIVE) | 0.659 | 20 | MAIVE (WAIVE) | 0.659 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
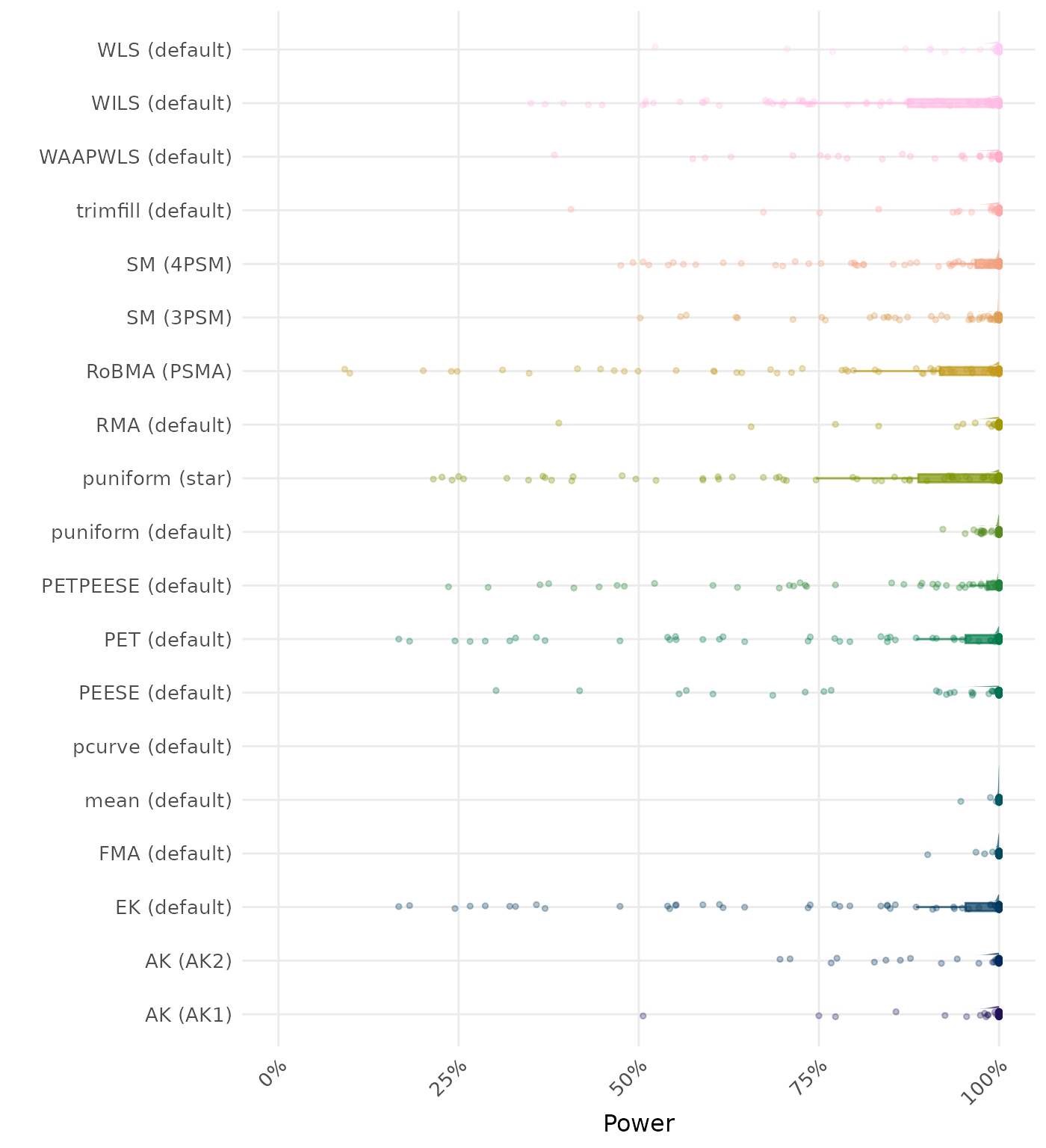
The power is the proportion of simulation runs in which the null hypothesis of no effect was correctly rejected when the alternative hypothesis was true. A higher power indicates a better method.
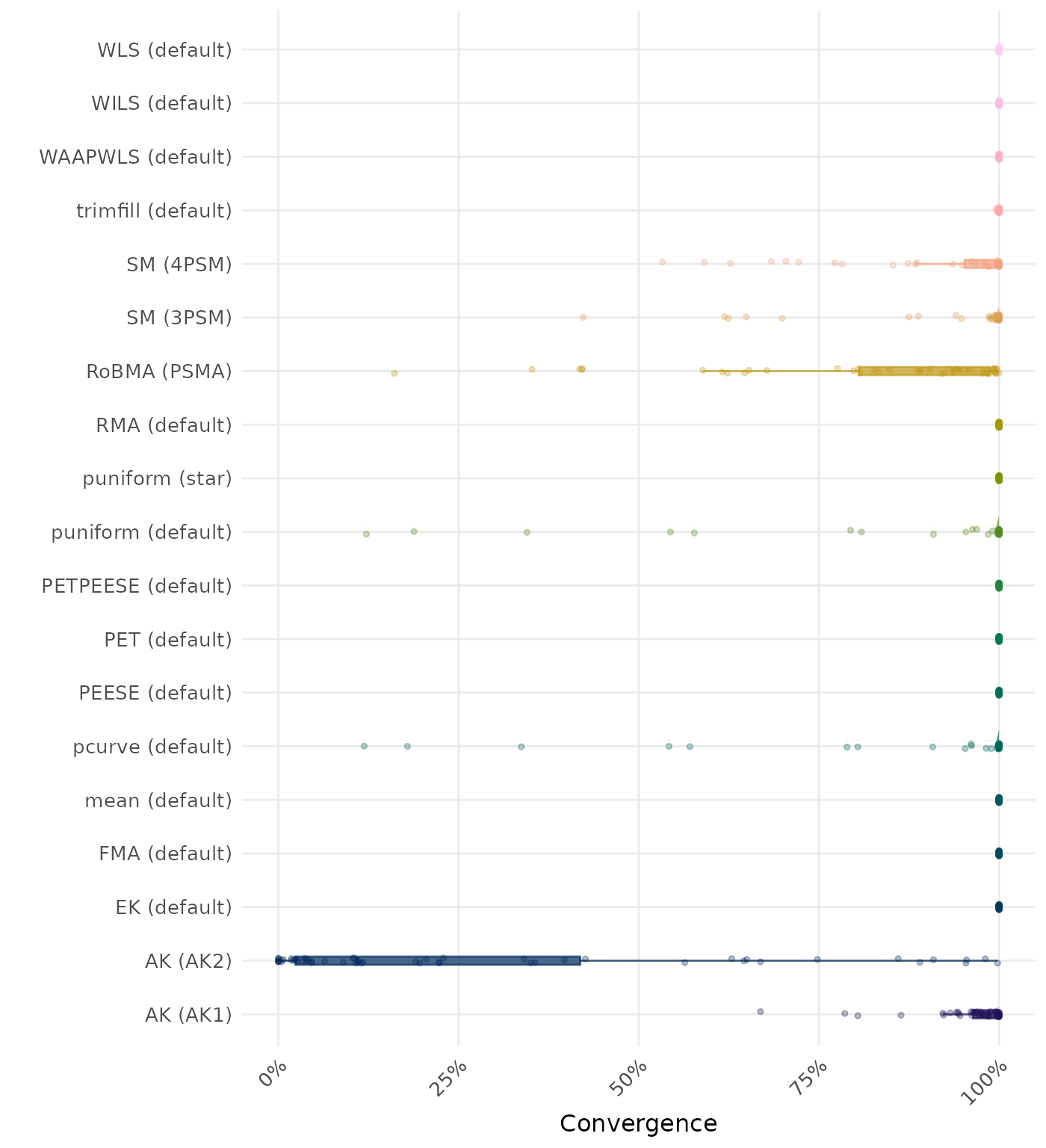
By-Condition Performance (Conditional on Method Convergence)
The results below are conditional on method convergence. Note that the methods might differ in convergence rate and are therefore not compared on the same data sets.
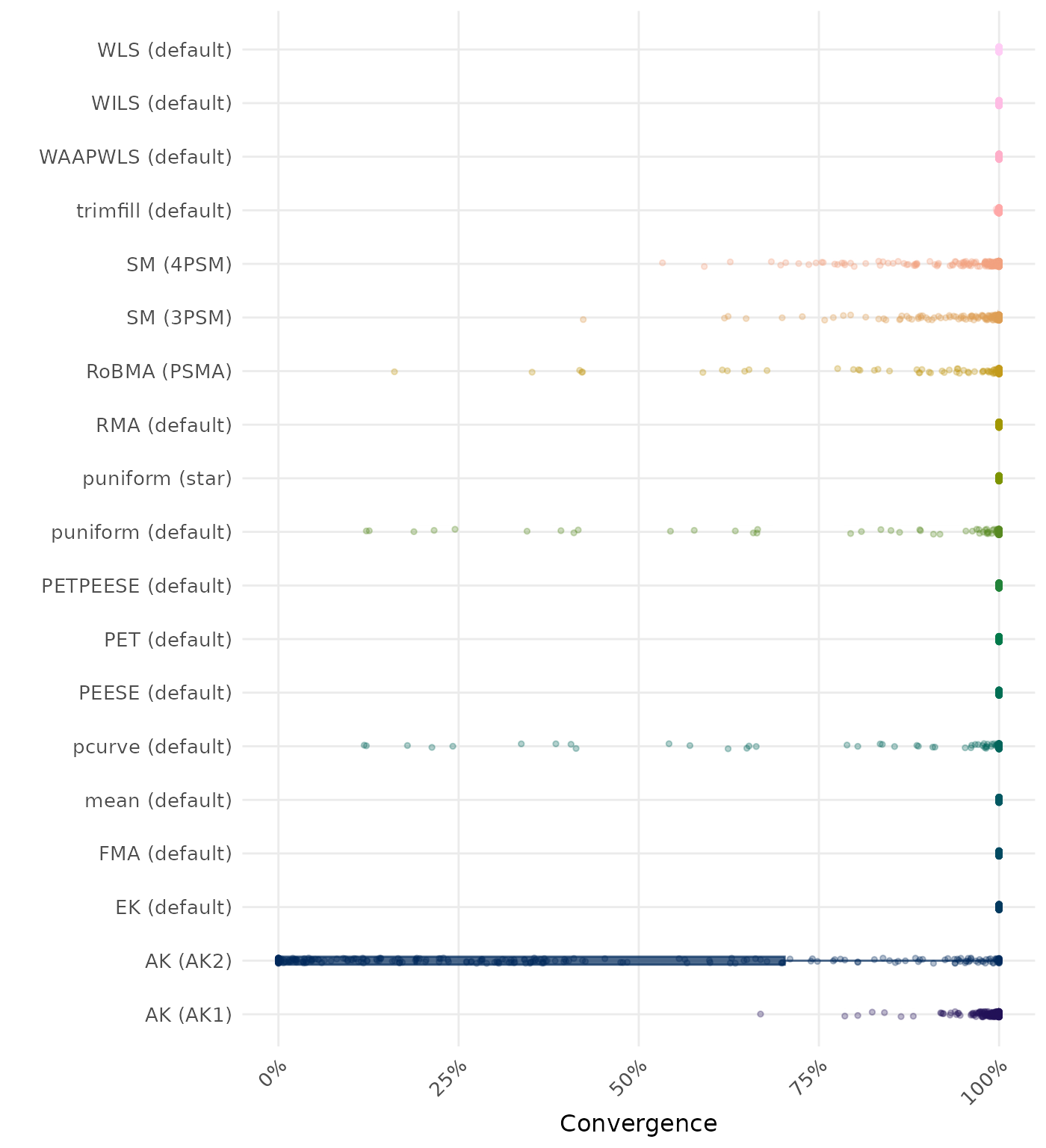
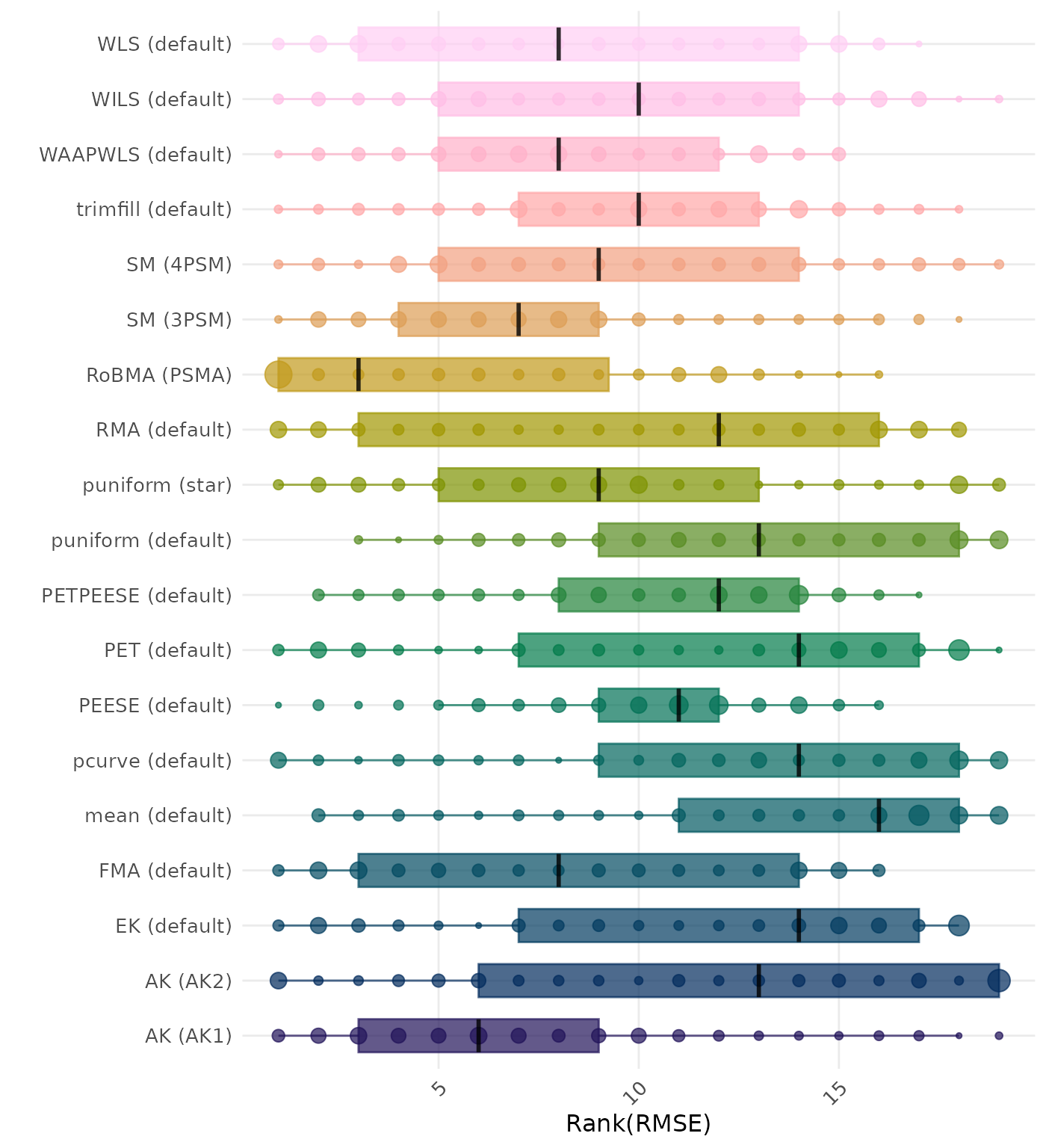
RMSE (Root Mean Square Error) is an overall summary measure of estimation performance that combines bias and empirical SE. RMSE is the square root of the average squared difference between the meta-analytic estimate and the true effect across simulation runs. A lower RMSE indicates a better method. Methods are compared using condition-wise ranks. Direct comparison using the average RMSE is not possible because the data-generating mechanisms differ in the outcome scale. See the DGM-specific results (or subresults) to see the distribution of RMSE values on the corresponding outcome scale.
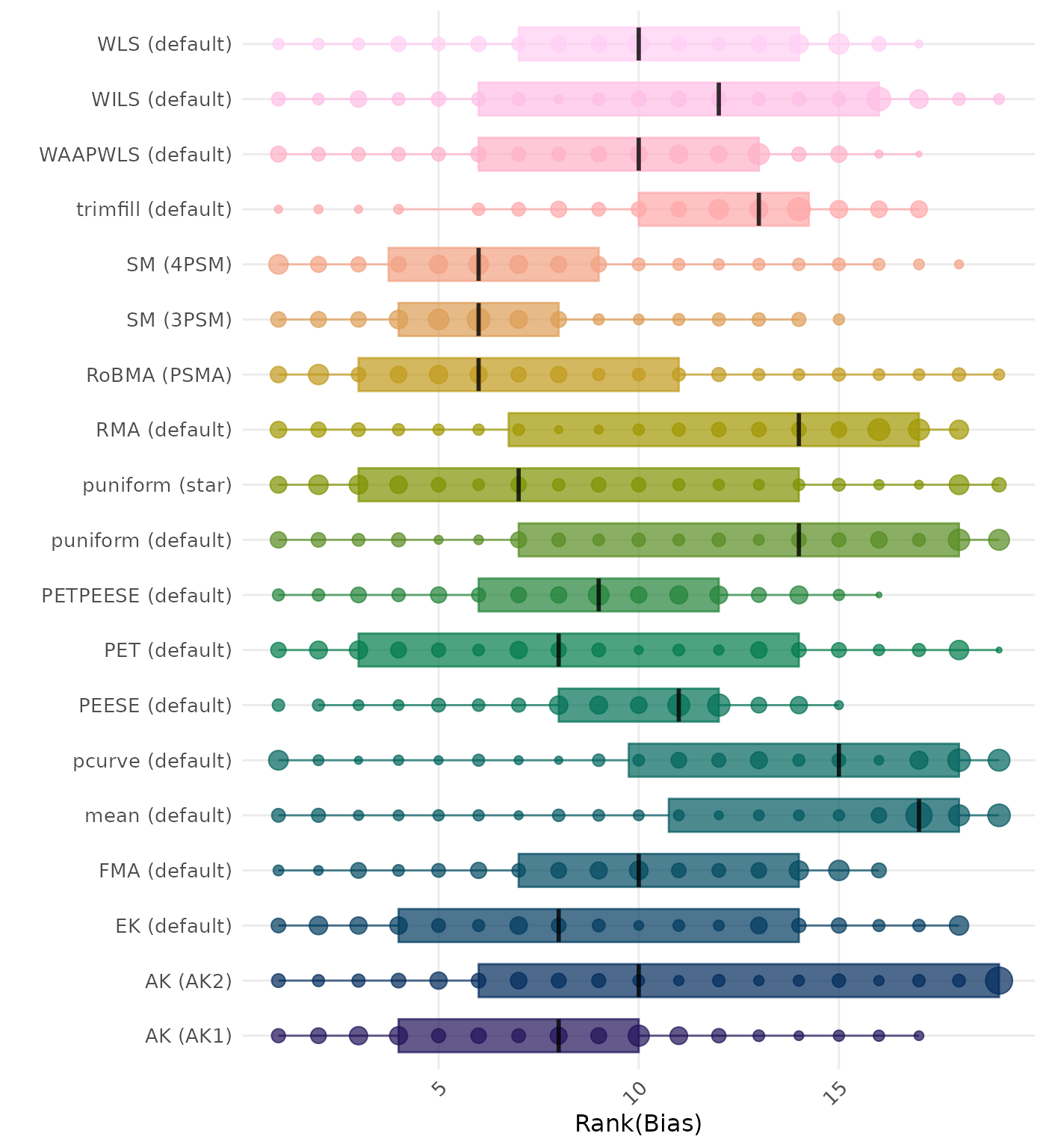
Bias is the average difference between the meta-analytic estimate and the true effect across simulation runs. Ideally, this value should be close to 0. Methods are compared using condition-wise ranks. Direct comparison using the average bias is not possible because the data-generating mechanisms differ in the outcome scale. See the DGM-specific results (or subresults) to see the distribution of bias values on the corresponding outcome scale.
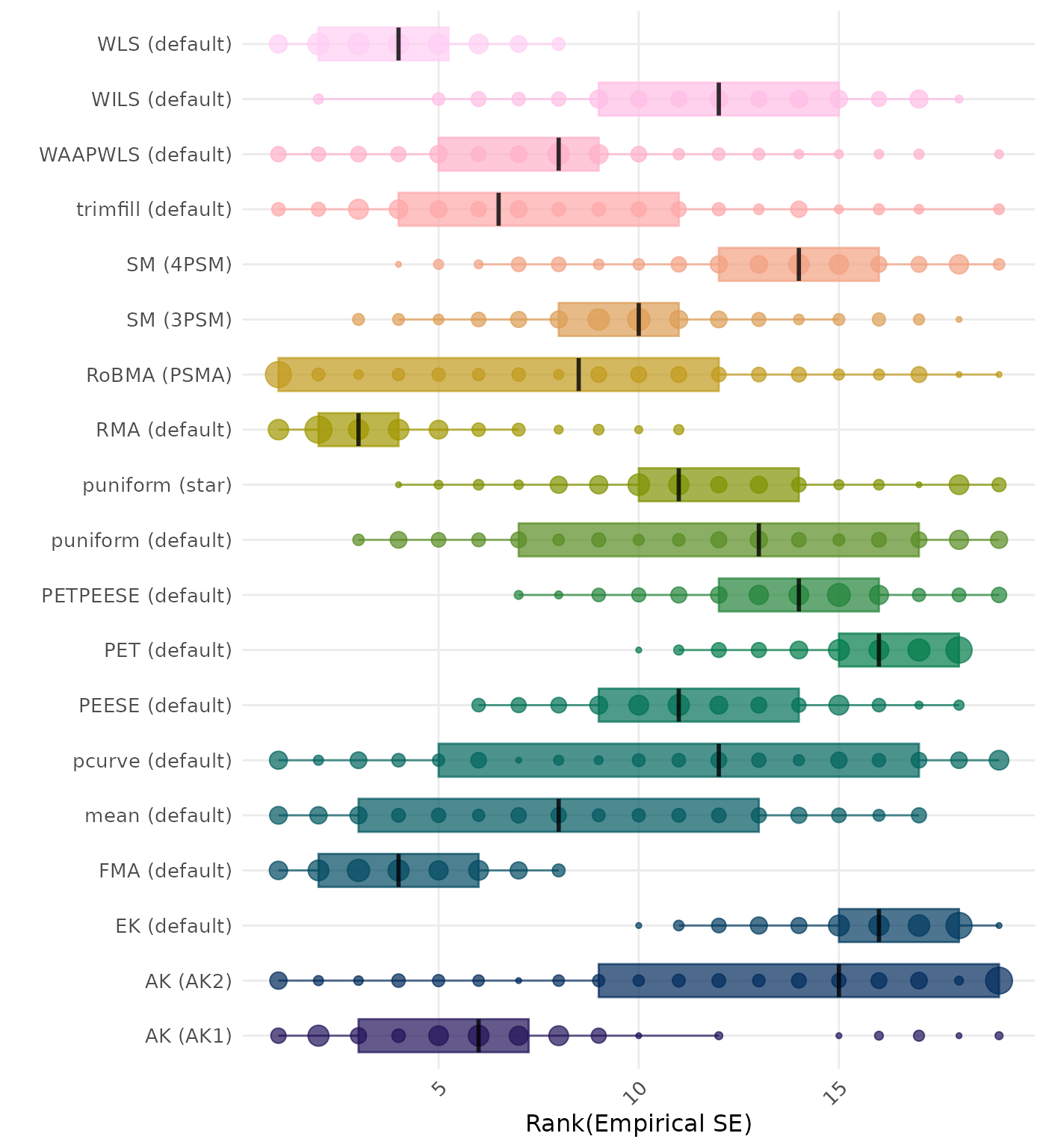
The empirical SE is the standard deviation of the meta-analytic estimate across simulation runs. A lower empirical SE indicates less variability and better method performance. Methods are compared using condition-wise ranks. Direct comparison using the empirical standard error is not possible because the data-generating mechanisms differ in the outcome scale. See the DGM-specific results (or subresults) to see the distribution of bias values on the corresponding outcome scale.
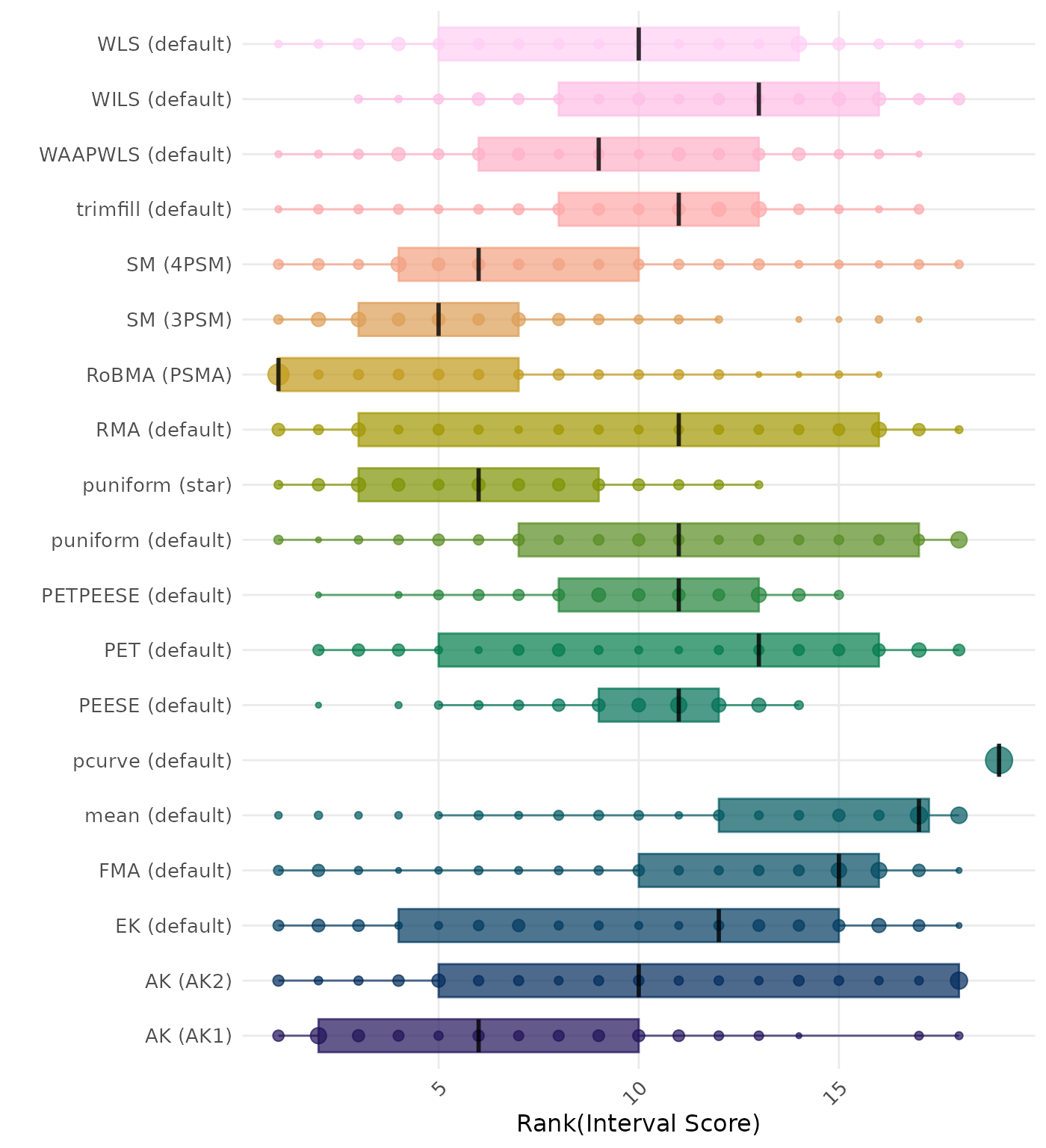
The interval score measures the accuracy of a confidence interval by combining its width and coverage. It penalizes intervals that are too wide or that fail to include the true value. A lower interval score indicates a better method. Methods are compared using condition-wise ranks. Direct comparison using the interval score is not possible because the data-generating mechanisms differ in the outcome scale. See the DGM-specific results (or subresults) to see the distribution of bias values on the corresponding outcome scale.

95% CI coverage is the proportion of simulation runs in which the 95% confidence interval contained the true effect. Ideally, this value should be close to the nominal level of 95%.
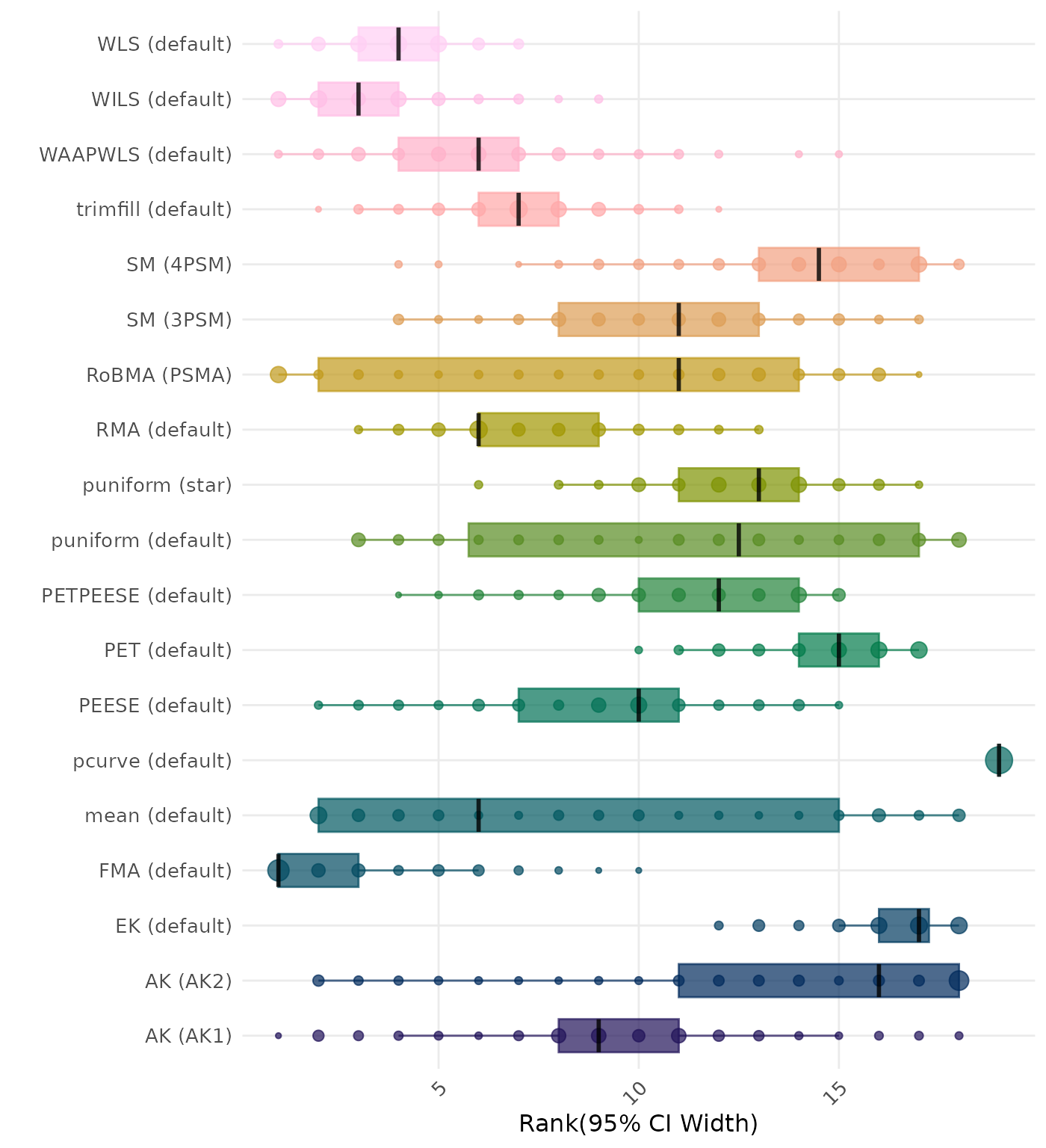
95% CI width is the average length of the 95% confidence interval for the true effect. A lower average 95% CI length indicates a better method. Methods are compared using condition-wise ranks. Direct comparison using the average 95% CI width is not possible because the data-generating mechanisms differ in the outcome scale. See the DGM-specific results (or subresults) to see the distribution of 95% CI width values on the corresponding outcome scale.
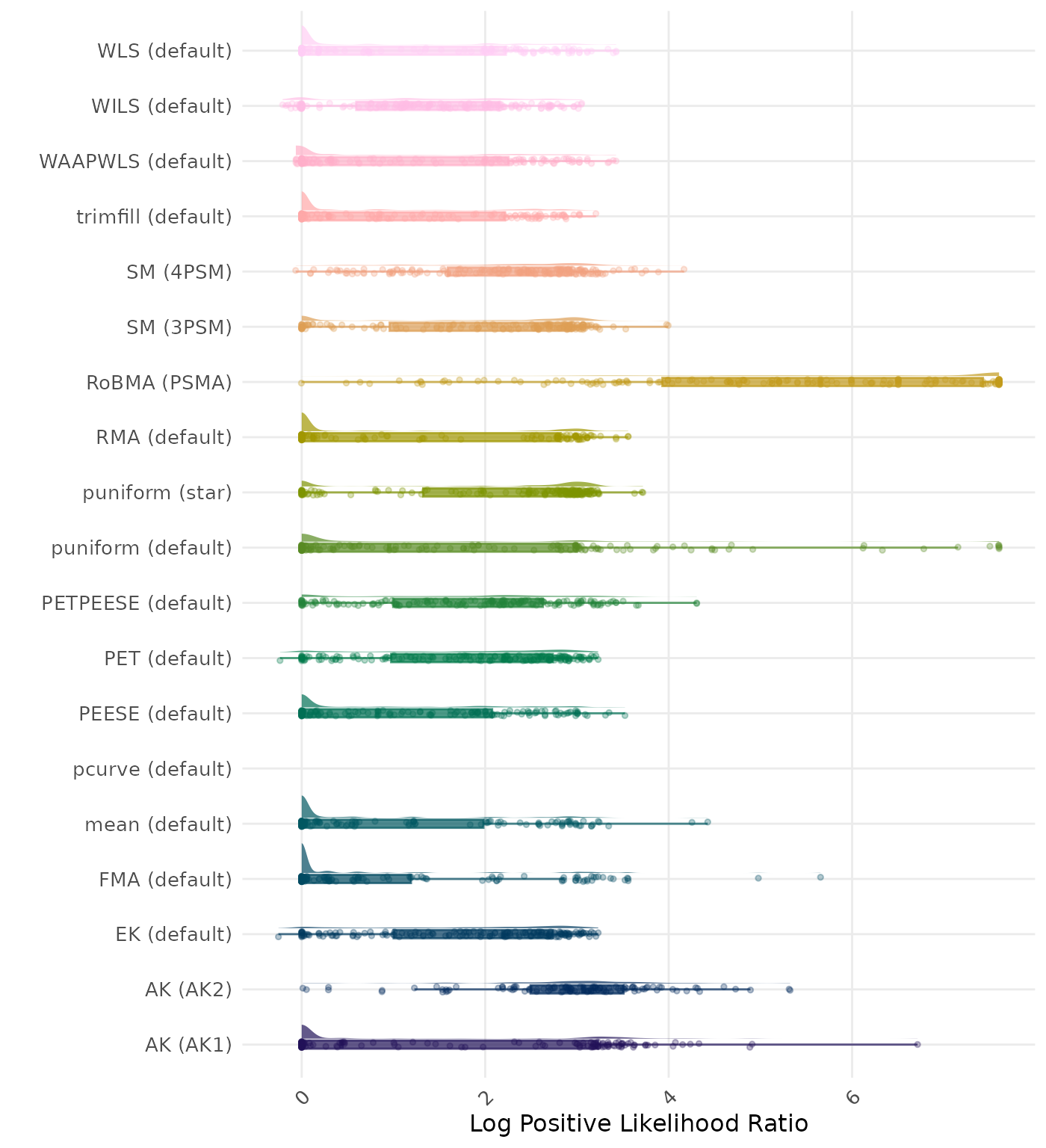
The positive likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a positive likelihood ratio greater than 1 (or a log positive likelihood ratio greater than 0). A higher (log) positive likelihood ratio indicates a better method.
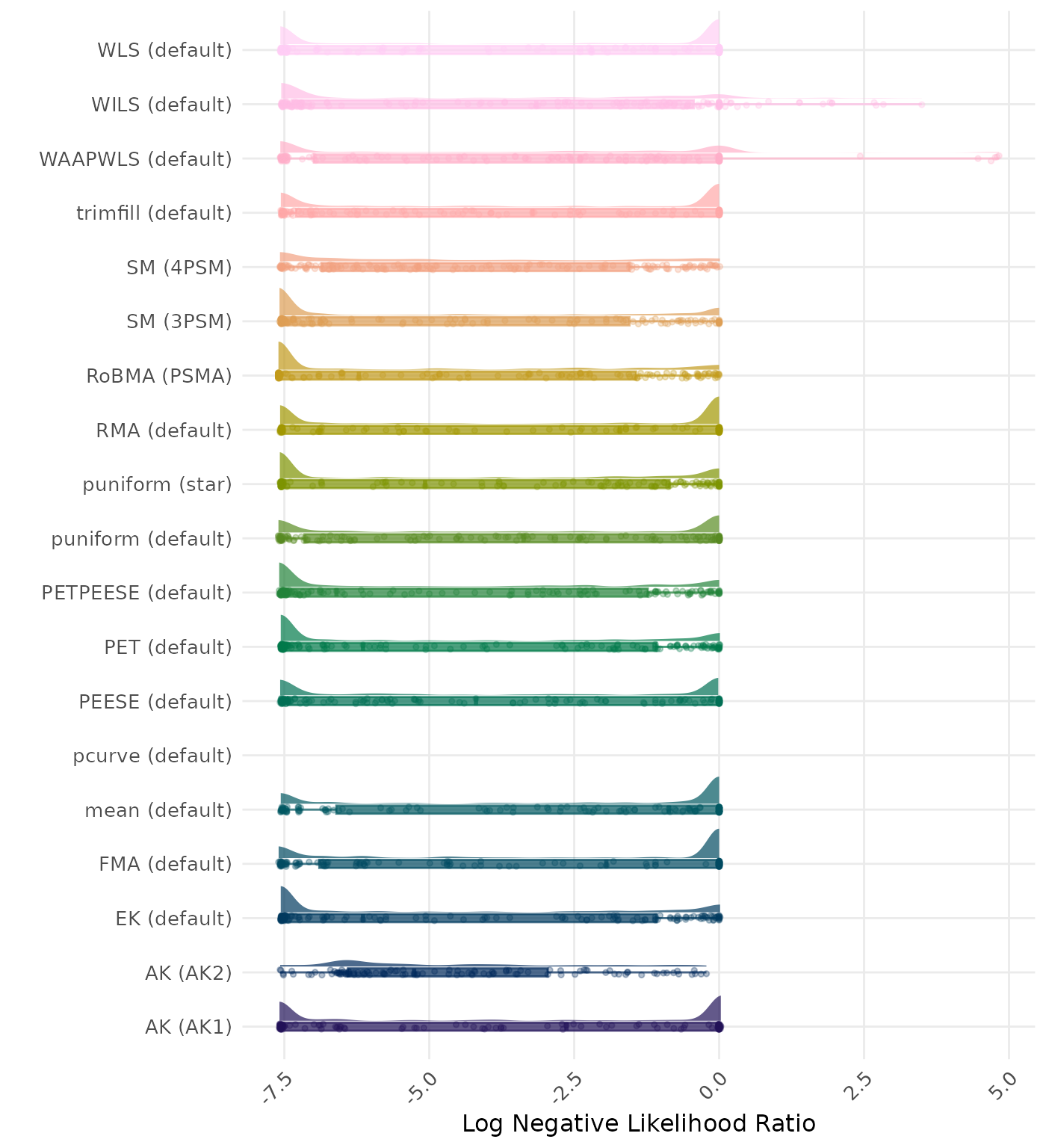
The negative likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a non-significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a negative likelihood ratio less than 1 (or a log negative likelihood ratio less than 0). A lower (log) negative likelihood ratio indicates a better method.
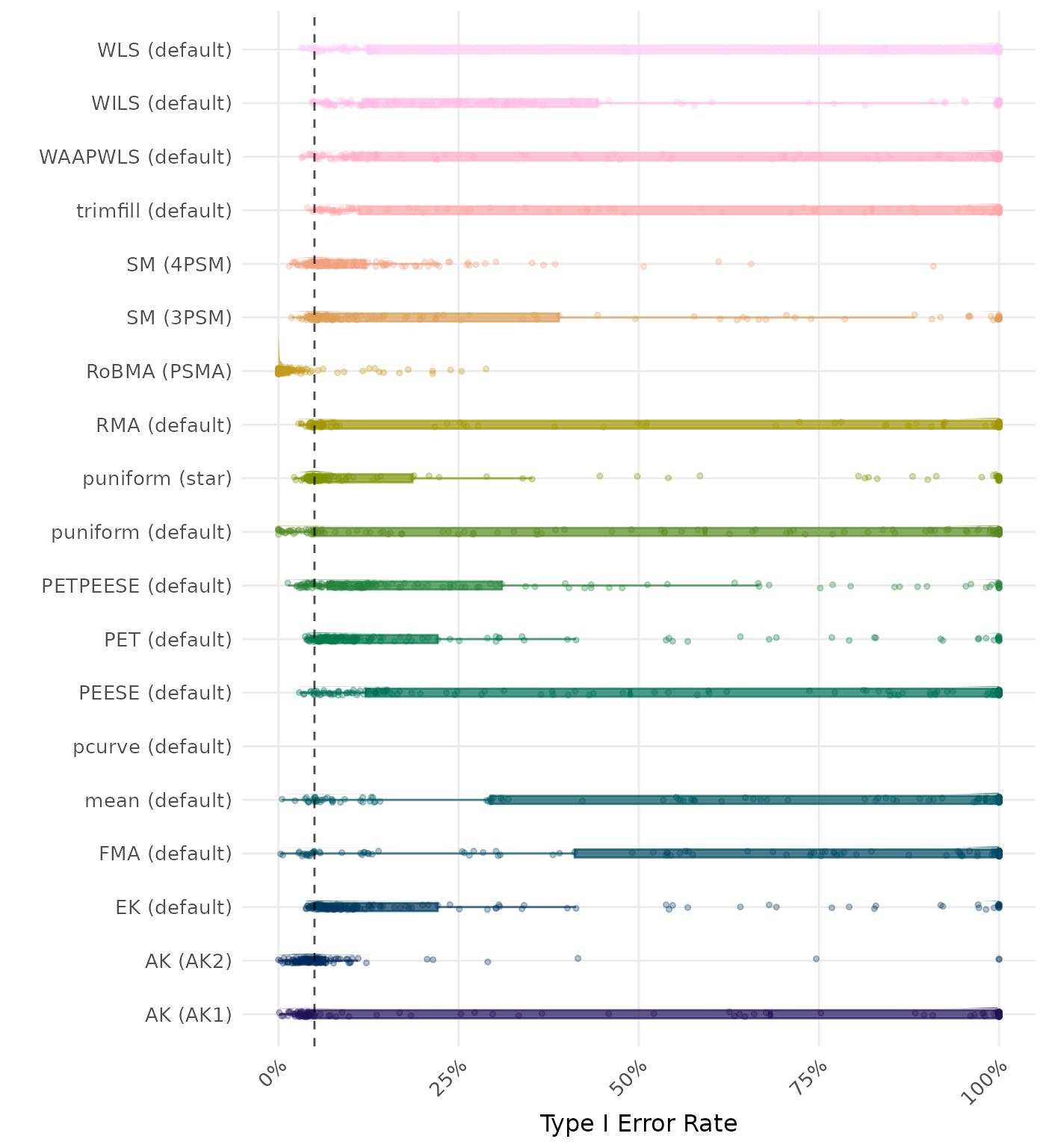
The type I error rate is the proportion of simulation runs in which the null hypothesis of no effect was incorrectly rejected when it was true. Ideally, this value should be close to the nominal level of 5%.
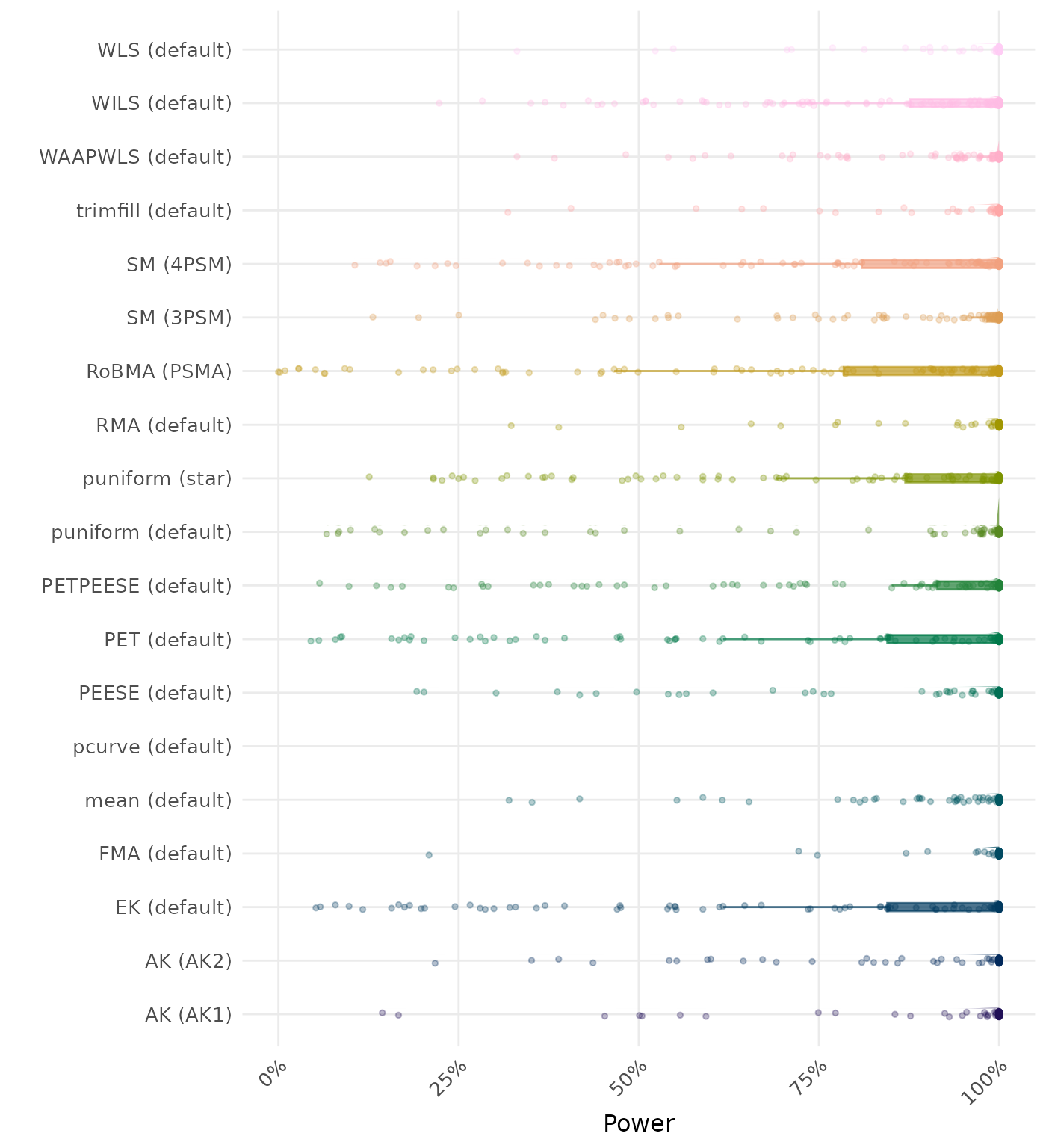
The power is the proportion of simulation runs in which the null hypothesis of no effect was correctly rejected when the alternative hypothesis was true. A higher power indicates a better method.
By-Condition Performance (Replacement in Case of Non-Convergence)
The results below incorporate method replacement to handle non-convergence. If a method fails to converge, its results are replaced with the results from a simpler method (e.g., random-effects meta-analysis without publication bias adjustment). This emulates what a data analyst may do in practice in case a method does not converge. However, note that these results do not correspond to “pure” method performance as they might combine multiple different methods. See Method Replacement Strategy for details of the method replacement specification.
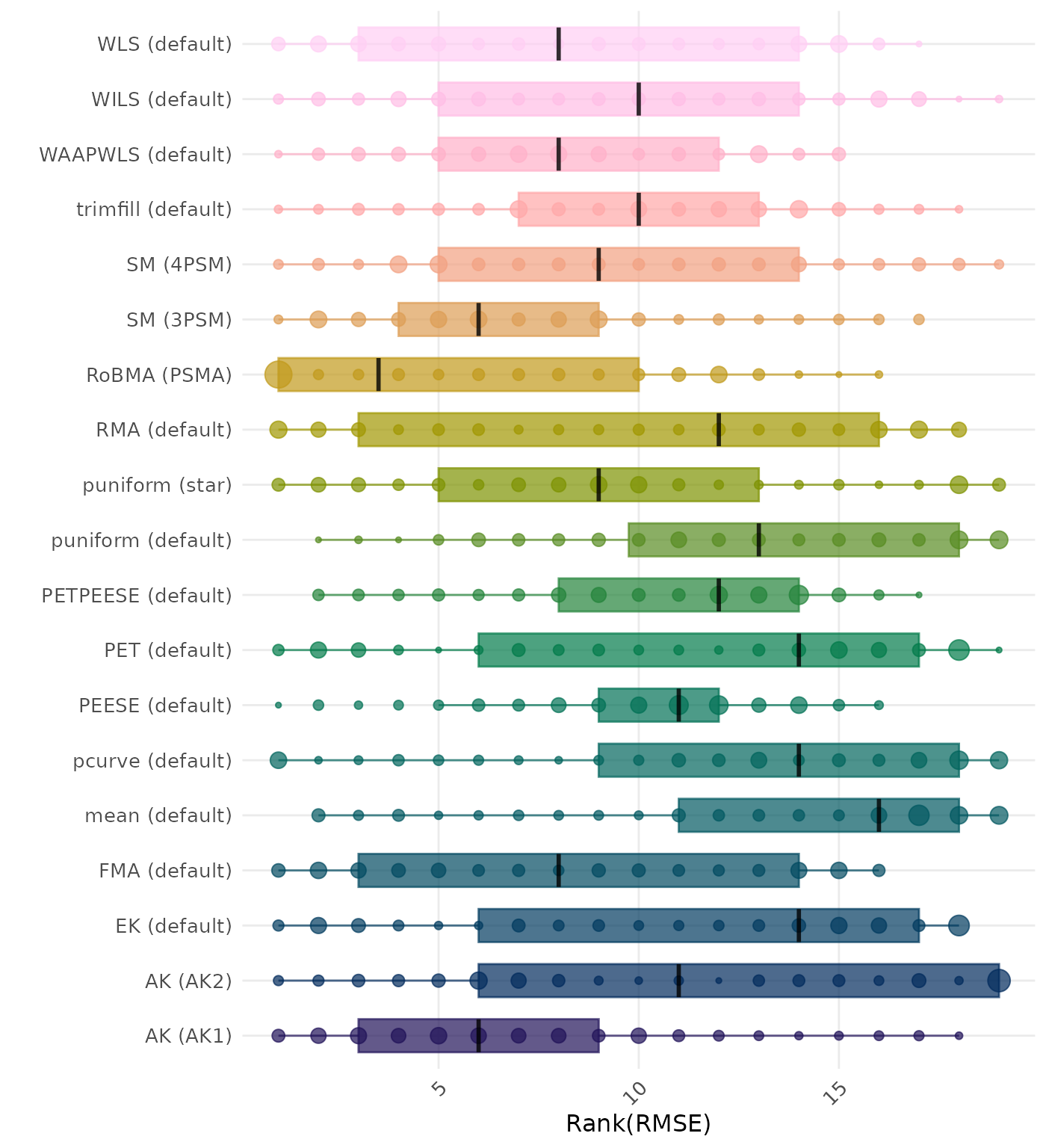
RMSE (Root Mean Square Error) is an overall summary measure of estimation performance that combines bias and empirical SE. RMSE is the square root of the average squared difference between the meta-analytic estimate and the true effect across simulation runs. A lower RMSE indicates a better method. Methods are compared using condition-wise ranks. Direct comparison using the average RMSE is not possible because the data-generating mechanisms differ in the outcome scale. See the DGM-specific results (or subresults) to see the distribution of RMSE values on the corresponding outcome scale.
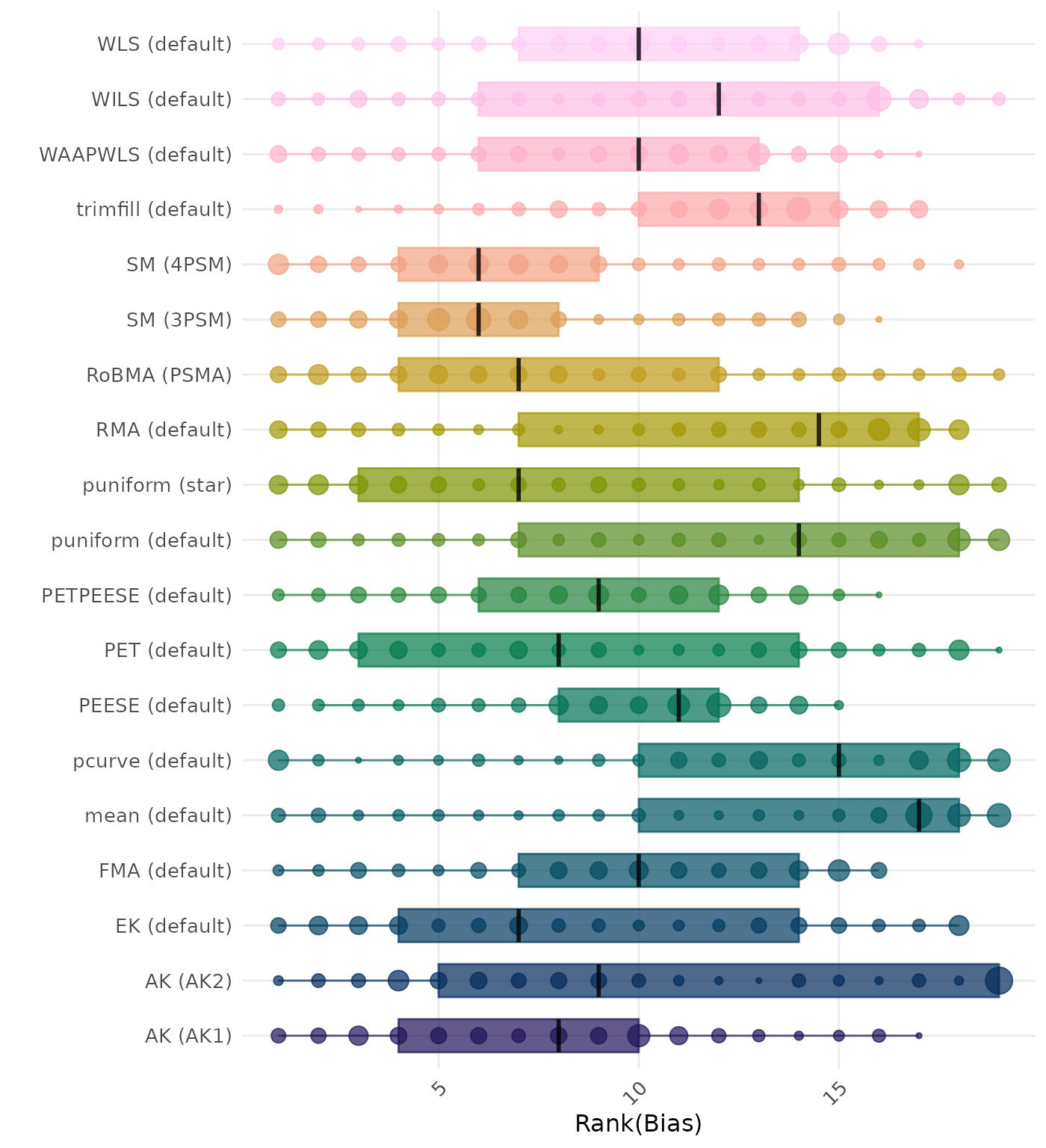
Bias is the average difference between the meta-analytic estimate and the true effect across simulation runs. Ideally, this value should be close to 0. Methods are compared using condition-wise ranks. Direct comparison using the average bias is not possible because the data-generating mechanisms differ in the outcome scale. See the DGM-specific results (or subresults) to see the distribution of bias values on the corresponding outcome scale.
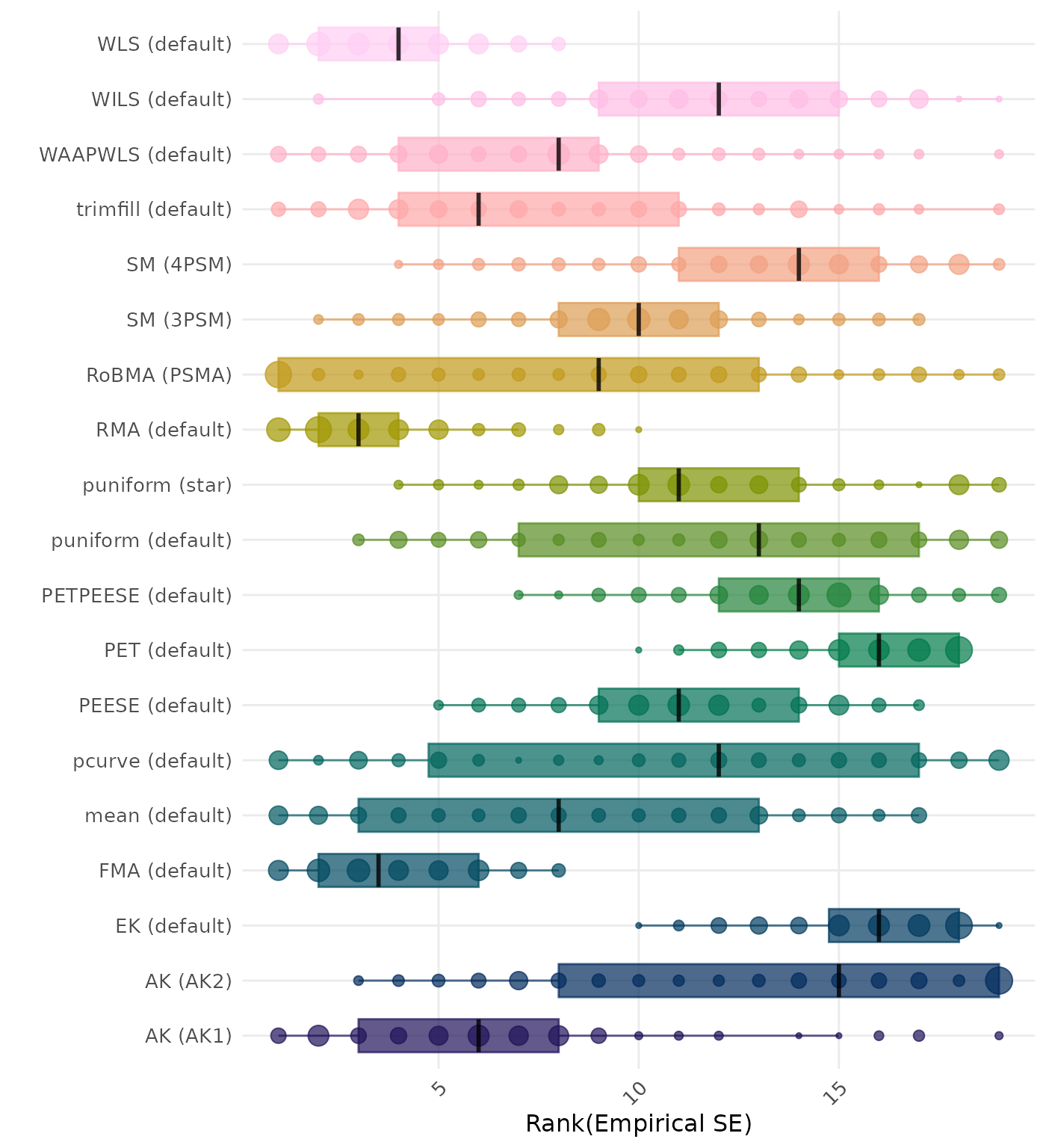
The empirical SE is the standard deviation of the meta-analytic estimate across simulation runs. A lower empirical SE indicates less variability and better method performance. Methods are compared using condition-wise ranks. Direct comparison using the empirical standard error is not possible because the data-generating mechanisms differ in the outcome scale. See the DGM-specific results (or subresults) to see the distribution of bias values on the corresponding outcome scale.
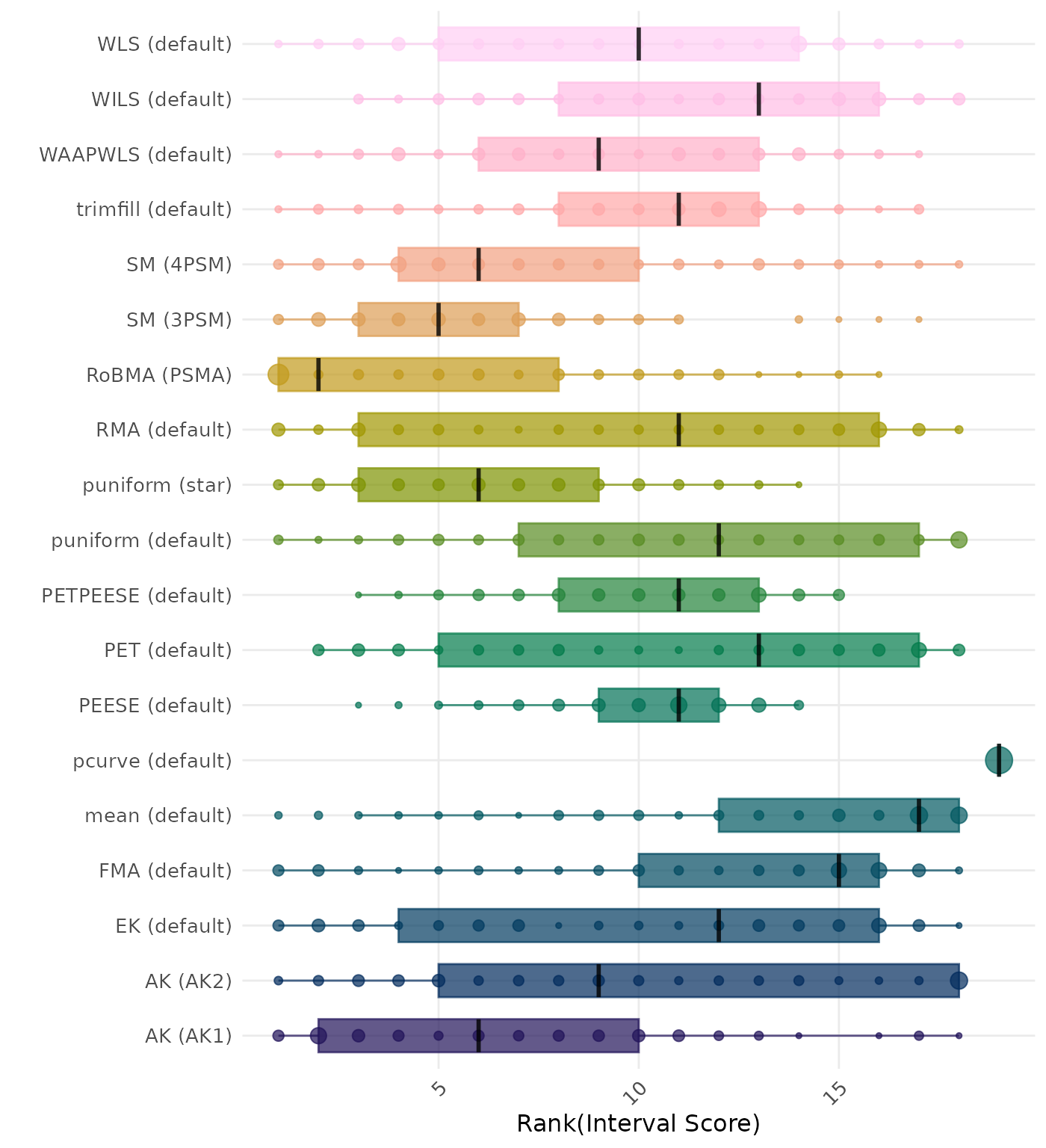
The interval score measures the accuracy of a confidence interval by combining its width and coverage. It penalizes intervals that are too wide or that fail to include the true value. A lower interval score indicates a better method. Methods are compared using condition-wise ranks. Direct comparison using the interval score is not possible because the data-generating mechanisms differ in the outcome scale. See the DGM-specific results (or subresults) to see the distribution of bias values on the corresponding outcome scale.
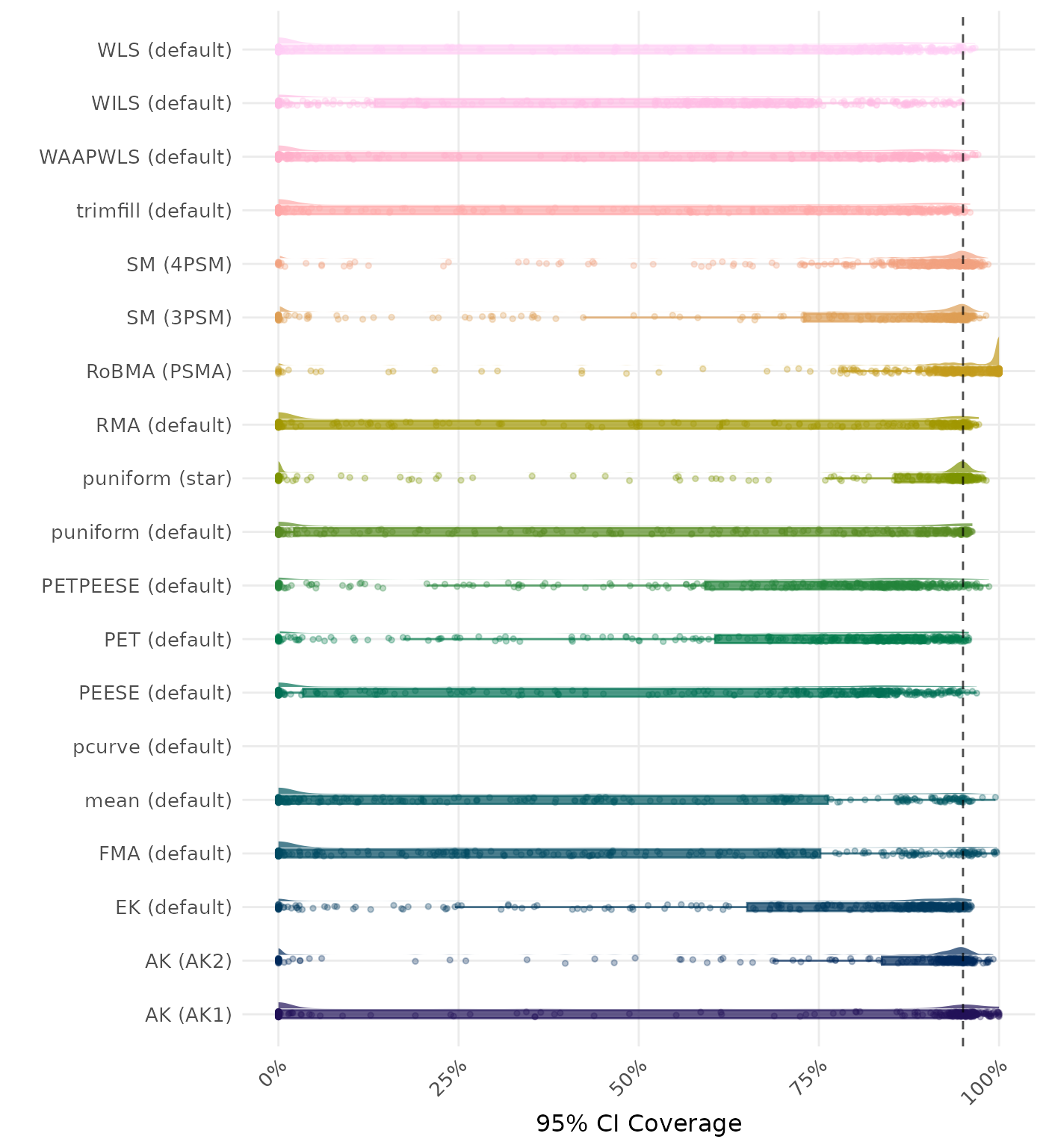
95% CI coverage is the proportion of simulation runs in which the 95% confidence interval contained the true effect. Ideally, this value should be close to the nominal level of 95%.
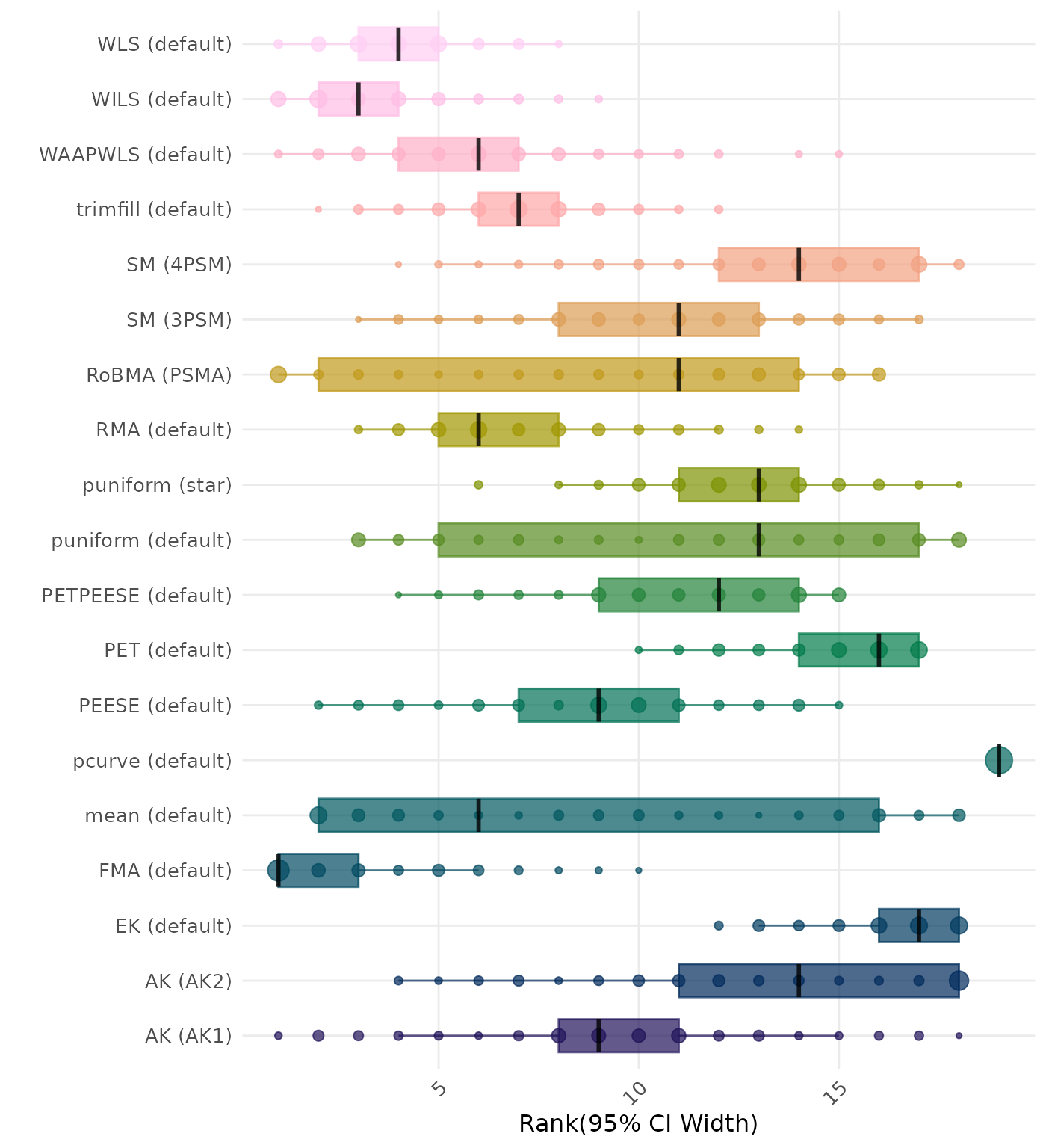
95% CI width is the average length of the 95% confidence interval for the true effect. A lower average 95% CI length indicates a better method. Methods are compared using condition-wise ranks. Direct comparison using the average 95% CI width is not possible because the data-generating mechanisms differ in the outcome scale. See the DGM-specific results (or subresults) to see the distribution of 95% CI width values on the corresponding outcome scale.
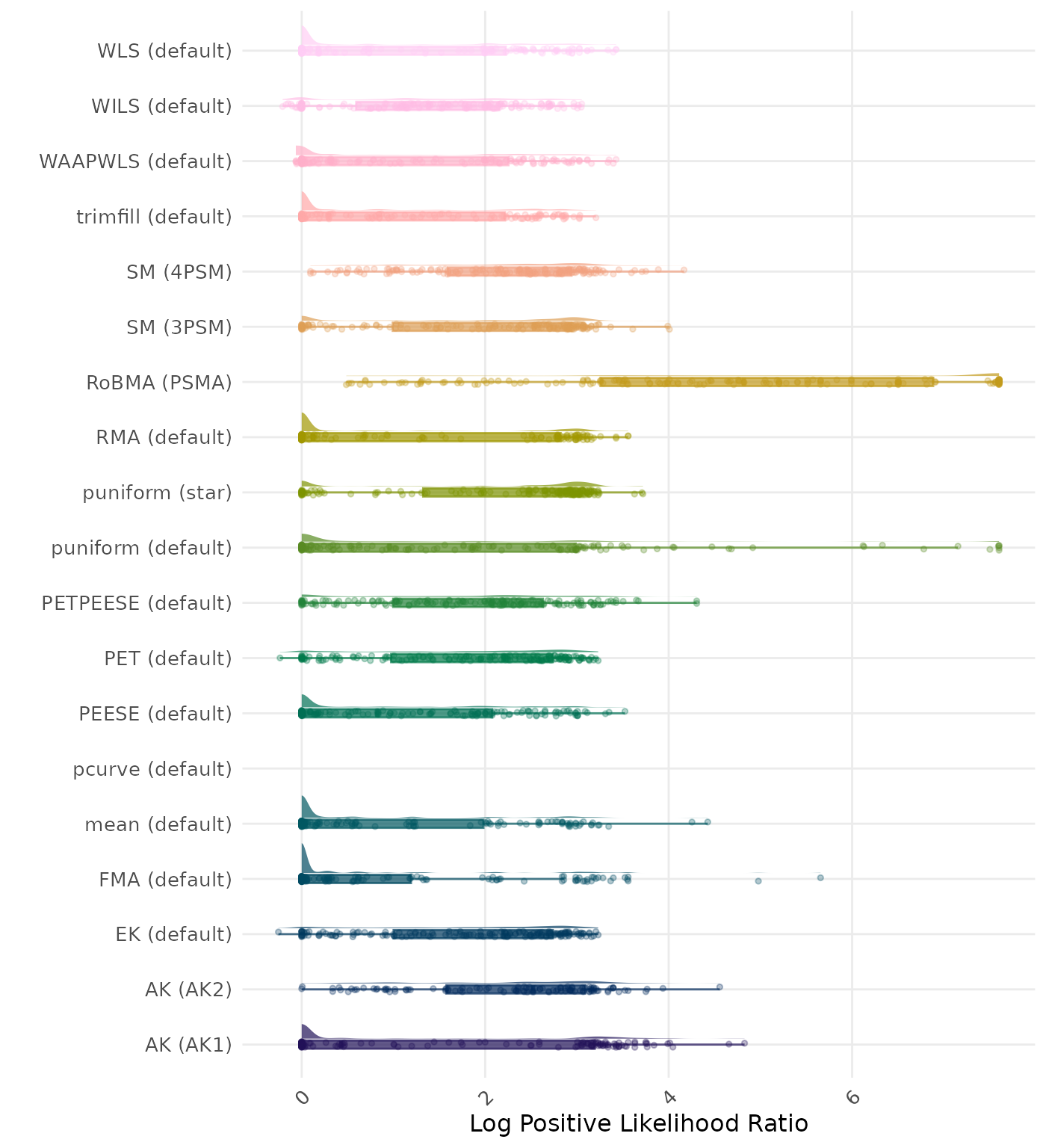
The positive likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a positive likelihood ratio greater than 1 (or a log positive likelihood ratio greater than 0). A higher (log) positive likelihood ratio indicates a better method.
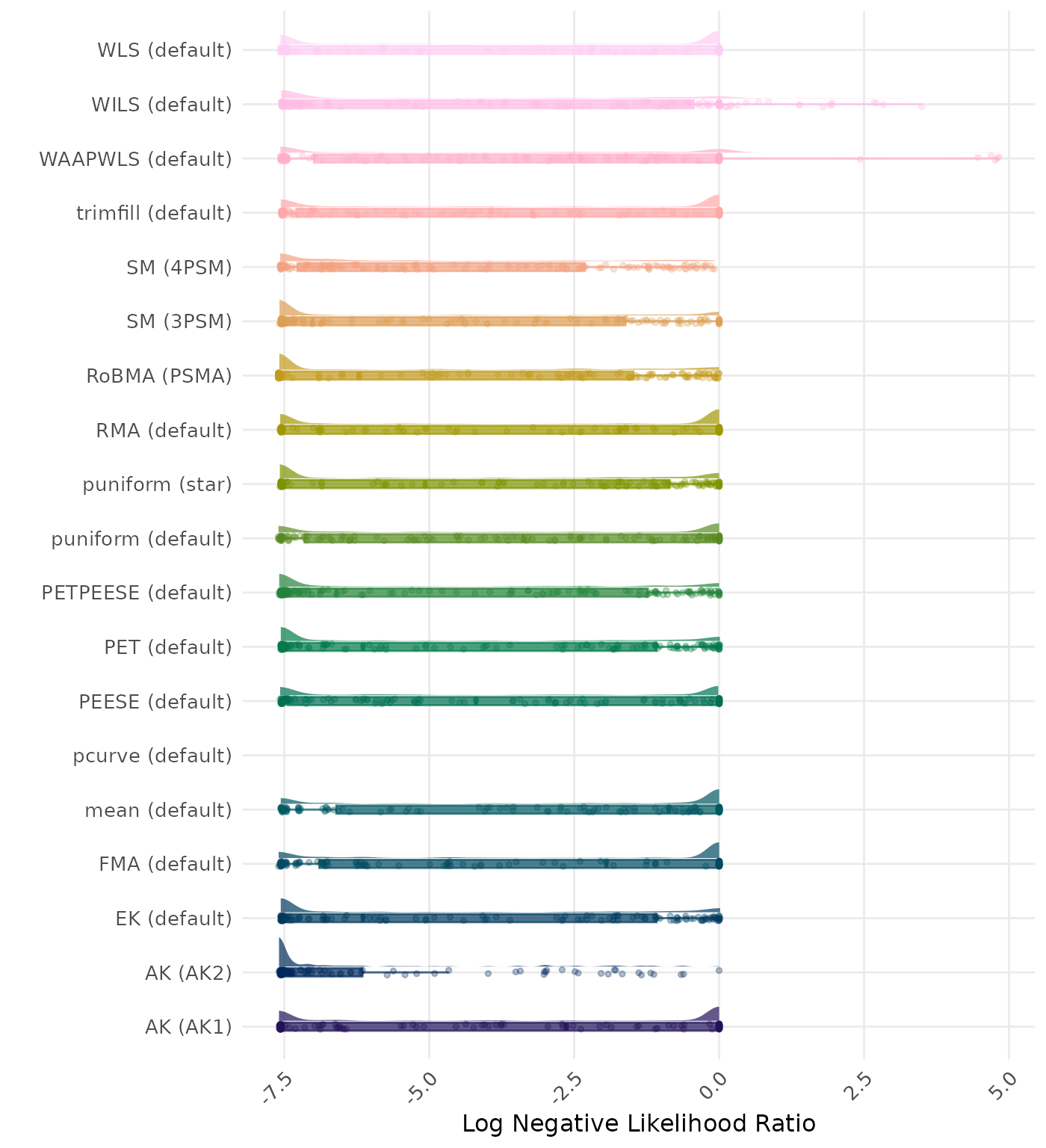
The negative likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a non-significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a negative likelihood ratio less than 1 (or a log negative likelihood ratio less than 0). A lower (log) negative likelihood ratio indicates a better method.
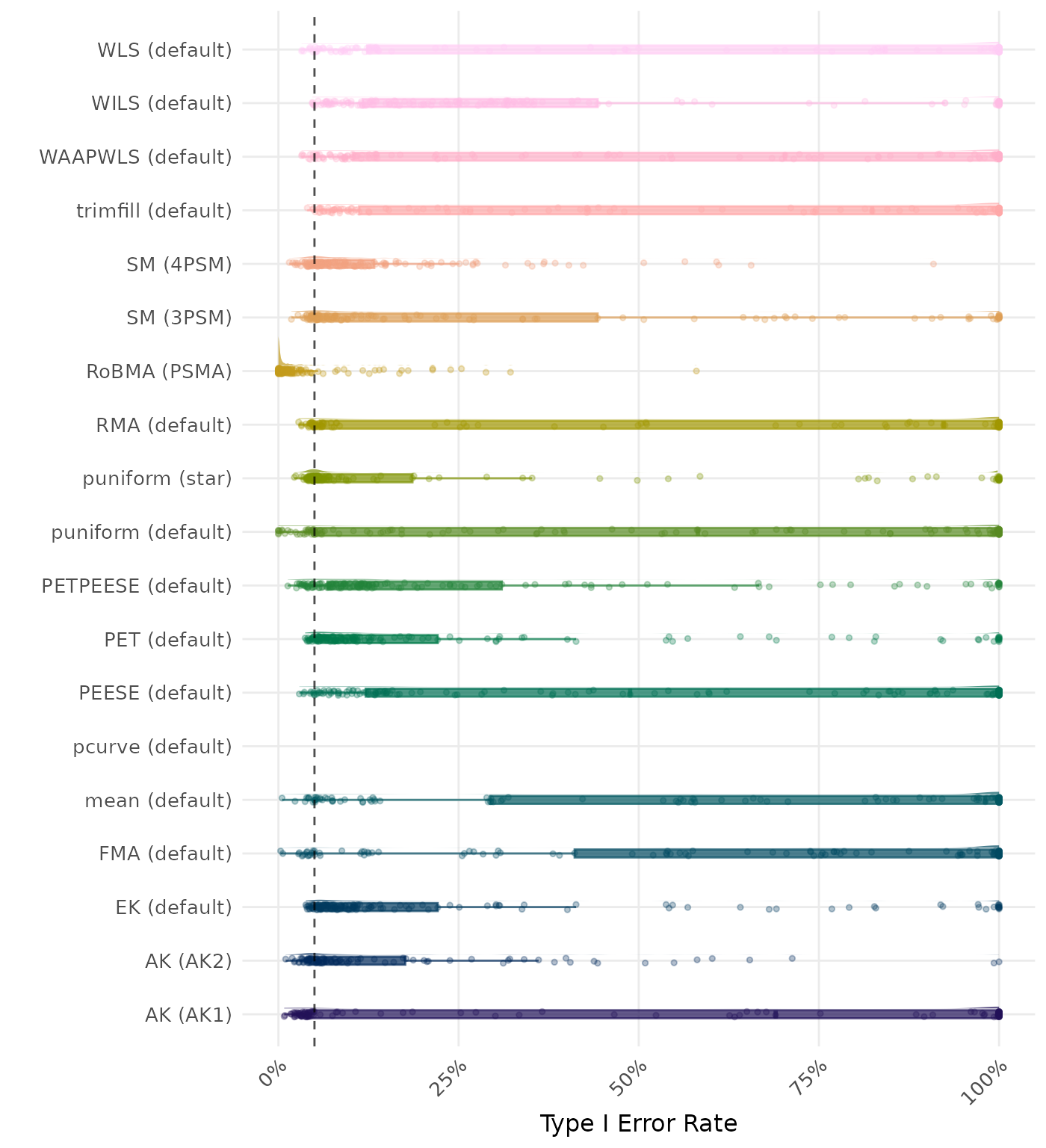
The type I error rate is the proportion of simulation runs in which the null hypothesis of no effect was incorrectly rejected when it was true. Ideally, this value should be close to the nominal level of 5%.
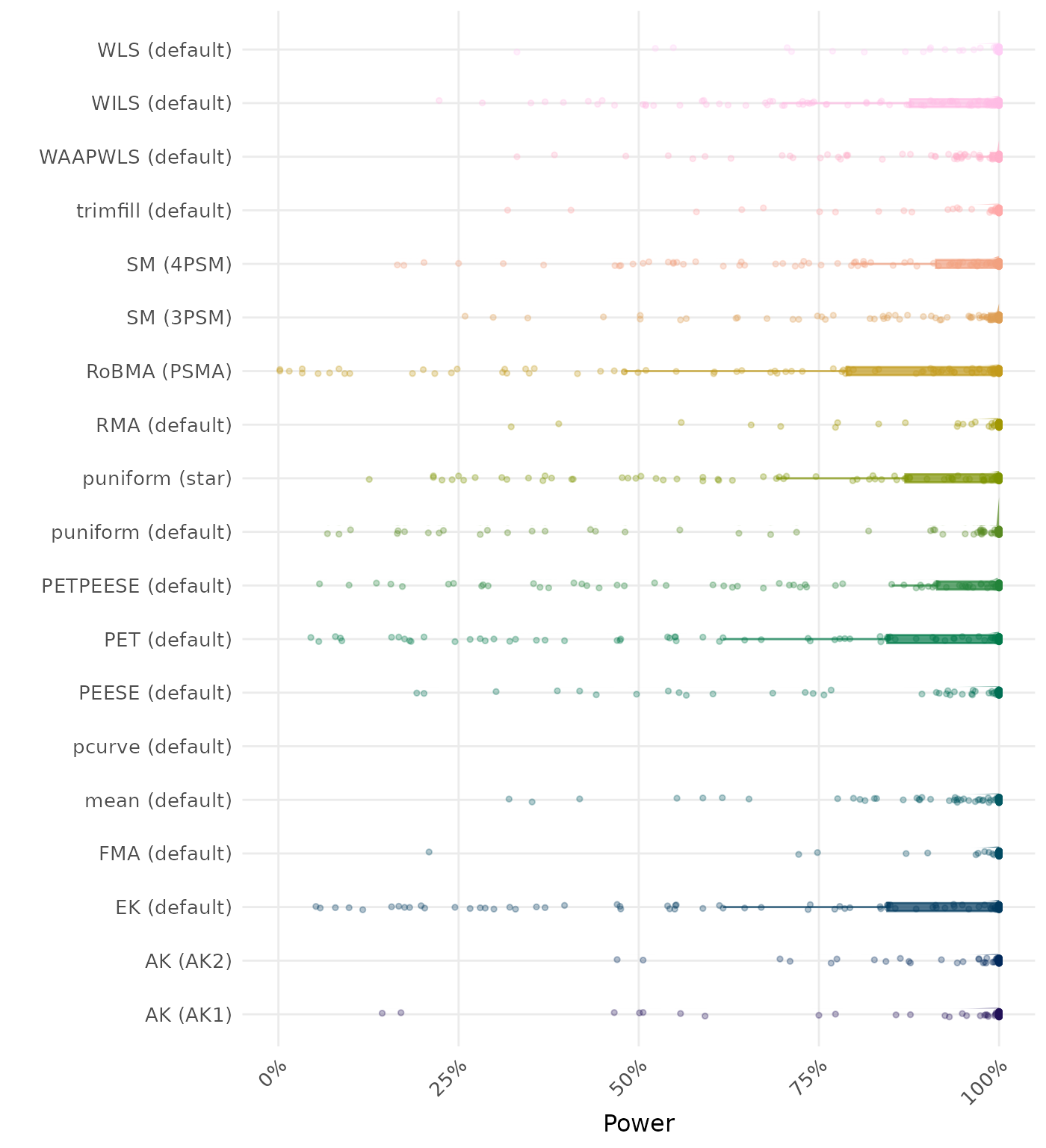
The power is the proportion of simulation runs in which the null hypothesis of no effect was correctly rejected when the alternative hypothesis was true. A higher power indicates a better method.
Subset: Standardized Mean Difference Effect Sizes
These results are based on Stanley (2017) data-generating mechanism with a total of 1 conditions.
Average Performance
Method performance measures are aggregated across all simulated conditions to provide an overall impression of method performance. However, keep in mind that a method with a high overall ranking is not necessarily the “best” method for a particular application. To select a suitable method for your application, consider also non-aggregated performance measures in conditions most relevant to your application.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | RoBMA (PSMA) | 0.057 | 1 | RoBMA (PSMA) | 0.057 |
| 2 | AK (AK2) | 0.067 | 2 | AK (AK2) | 0.083 |
| 3 | WILS (default) | 0.095 | 3 | WILS (default) | 0.095 |
| 4 | PEESE (default) | 0.105 | 4 | PEESE (default) | 0.105 |
| 5 | WAAPWLS (default) | 0.108 | 5 | WAAPWLS (default) | 0.108 |
| 6 | PETPEESE (default) | 0.109 | 6 | PETPEESE (default) | 0.109 |
| 7 | trimfill (default) | 0.111 | 7 | trimfill (default) | 0.111 |
| 8 | MAIVE (default) | 0.112 | 8 | MAIVE (default) | 0.112 |
| 9 | FMA (default) | 0.112 | 9 | FMA (default) | 0.112 |
| 9 | WLS (default) | 0.112 | 9 | WLS (default) | 0.112 |
| 11 | EK (default) | 0.119 | 11 | EK (default) | 0.119 |
| 12 | PET (default) | 0.119 | 12 | PET (default) | 0.119 |
| 13 | RMA (default) | 0.123 | 13 | RMA (default) | 0.123 |
| 14 | SM (3PSM) | 0.130 | 14 | SM (3PSM) | 0.126 |
| 15 | mean (default) | 0.146 | 15 | mean (default) | 0.146 |
| 16 | AK (AK1) | 0.163 | 16 | AK (AK1) | 0.158 |
| 17 | MAIVE (WAIVE) | 0.173 | 17 | MAIVE (WAIVE) | 0.173 |
| 18 | SM (4PSM) | 0.202 | 18 | SM (4PSM) | 0.203 |
| 19 | pcurve (default) | 0.467 | 19 | pcurve (default) | 0.420 |
| 20 | puniform (default) | 0.648 | 20 | puniform (default) | 0.545 |
| 21 | puniform (star) | 90.749 | 21 | puniform (star) | 90.749 |
RMSE (Root Mean Square Error) is an overall summary measure of estimation performance that combines bias and empirical SE. RMSE is the square root of the average squared difference between the meta-analytic estimate and the true effect across simulation runs. A lower RMSE indicates a better method.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | RoBMA (PSMA) | 0.006 | 1 | RoBMA (PSMA) | 0.006 |
| 2 | WILS (default) | 0.007 | 2 | WILS (default) | 0.007 |
| 3 | AK (AK2) | 0.010 | 3 | AK (AK2) | 0.011 |
| 4 | PET (default) | 0.015 | 4 | PET (default) | 0.015 |
| 5 | EK (default) | 0.015 | 5 | EK (default) | 0.015 |
| 6 | SM (4PSM) | -0.023 | 6 | SM (4PSM) | -0.022 |
| 7 | SM (3PSM) | 0.023 | 7 | SM (3PSM) | 0.025 |
| 8 | PETPEESE (default) | 0.036 | 8 | PETPEESE (default) | 0.036 |
| 9 | MAIVE (default) | 0.040 | 9 | MAIVE (default) | 0.040 |
| 10 | MAIVE (WAIVE) | -0.042 | 10 | MAIVE (WAIVE) | -0.042 |
| 11 | PEESE (default) | 0.057 | 11 | PEESE (default) | 0.057 |
| 12 | AK (AK1) | 0.060 | 12 | AK (AK1) | 0.061 |
| 13 | trimfill (default) | 0.069 | 13 | trimfill (default) | 0.069 |
| 14 | WAAPWLS (default) | 0.076 | 14 | WAAPWLS (default) | 0.076 |
| 15 | FMA (default) | 0.085 | 15 | FMA (default) | 0.085 |
| 15 | WLS (default) | 0.085 | 15 | WLS (default) | 0.085 |
| 17 | puniform (default) | 0.088 | 17 | RMA (default) | 0.103 |
| 18 | RMA (default) | 0.103 | 18 | puniform (default) | 0.103 |
| 19 | mean (default) | 0.125 | 19 | mean (default) | 0.125 |
| 20 | pcurve (default) | 0.322 | 20 | pcurve (default) | 0.260 |
| 21 | puniform (star) | -9.762 | 21 | puniform (star) | -9.762 |
Bias is the average difference between the meta-analytic estimate and the true effect across simulation runs. Ideally, this value should be close to 0.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | RMA (default) | 0.038 | 1 | RMA (default) | 0.038 |
| 2 | mean (default) | 0.042 | 2 | mean (default) | 0.042 |
| 3 | FMA (default) | 0.043 | 3 | FMA (default) | 0.043 |
| 3 | WLS (default) | 0.043 | 3 | WLS (default) | 0.043 |
| 5 | RoBMA (PSMA) | 0.045 | 5 | RoBMA (PSMA) | 0.045 |
| 6 | trimfill (default) | 0.046 | 6 | trimfill (default) | 0.046 |
| 7 | WAAPWLS (default) | 0.047 | 7 | WAAPWLS (default) | 0.047 |
| 8 | PEESE (default) | 0.058 | 8 | PEESE (default) | 0.058 |
| 9 | AK (AK2) | 0.059 | 9 | WILS (default) | 0.063 |
| 10 | WILS (default) | 0.063 | 10 | AK (AK2) | 0.076 |
| 11 | PETPEESE (default) | 0.079 | 11 | PETPEESE (default) | 0.079 |
| 12 | MAIVE (default) | 0.081 | 12 | MAIVE (default) | 0.081 |
| 13 | EK (default) | 0.095 | 13 | EK (default) | 0.095 |
| 14 | PET (default) | 0.095 | 14 | PET (default) | 0.095 |
| 15 | SM (3PSM) | 0.111 | 15 | SM (3PSM) | 0.107 |
| 16 | AK (AK1) | 0.113 | 16 | AK (AK1) | 0.109 |
| 17 | MAIVE (WAIVE) | 0.137 | 17 | MAIVE (WAIVE) | 0.137 |
| 18 | SM (4PSM) | 0.200 | 18 | SM (4PSM) | 0.201 |
| 19 | pcurve (default) | 0.290 | 19 | pcurve (default) | 0.286 |
| 20 | puniform (default) | 0.550 | 20 | puniform (default) | 0.448 |
| 21 | puniform (star) | 89.867 | 21 | puniform (star) | 89.867 |
The empirical SE is the standard deviation of the meta-analytic estimate across simulation runs. A lower empirical SE indicates less variability and better method performance.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | RoBMA (PSMA) | 0.271 | 1 | RoBMA (PSMA) | 0.271 |
| 2 | AK (AK2) | 0.508 | 2 | AK (AK2) | 0.641 |
| 3 | puniform (star) | 0.914 | 3 | SM (4PSM) | 0.891 |
| 4 | EK (default) | 1.027 | 4 | puniform (star) | 0.914 |
| 5 | SM (3PSM) | 1.058 | 5 | EK (default) | 1.027 |
| 6 | PET (default) | 1.097 | 6 | SM (3PSM) | 1.042 |
| 7 | SM (4PSM) | 1.140 | 7 | PET (default) | 1.097 |
| 8 | MAIVE (default) | 1.358 | 8 | MAIVE (default) | 1.358 |
| 9 | MAIVE (WAIVE) | 1.399 | 9 | MAIVE (WAIVE) | 1.399 |
| 10 | PETPEESE (default) | 1.536 | 10 | PETPEESE (default) | 1.536 |
| 11 | WILS (default) | 1.658 | 11 | WILS (default) | 1.658 |
| 12 | PEESE (default) | 1.834 | 12 | PEESE (default) | 1.834 |
| 13 | WAAPWLS (default) | 2.206 | 13 | WAAPWLS (default) | 2.206 |
| 14 | trimfill (default) | 2.263 | 14 | trimfill (default) | 2.263 |
| 15 | WLS (default) | 2.545 | 15 | WLS (default) | 2.545 |
| 16 | RMA (default) | 2.805 | 16 | RMA (default) | 2.805 |
| 17 | FMA (default) | 3.110 | 17 | FMA (default) | 3.110 |
| 18 | AK (AK1) | 3.353 | 18 | AK (AK1) | 3.157 |
| 19 | puniform (default) | 4.061 | 19 | puniform (default) | 3.890 |
| 20 | mean (default) | 4.067 | 20 | mean (default) | 4.067 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
The interval score measures the accuracy of a confidence interval by combining its width and coverage. It penalizes intervals that are too wide or that fail to include the true value. A lower interval score indicates a better method.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | RoBMA (PSMA) | 0.950 | 1 | RoBMA (PSMA) | 0.950 |
| 2 | SM (4PSM) | 0.924 | 2 | SM (4PSM) | 0.911 |
| 3 | AK (AK2) | 0.902 | 3 | AK (AK2) | 0.904 |
| 4 | puniform (star) | 0.830 | 4 | puniform (star) | 0.830 |
| 5 | MAIVE (default) | 0.827 | 5 | MAIVE (default) | 0.827 |
| 6 | SM (3PSM) | 0.807 | 6 | SM (3PSM) | 0.802 |
| 7 | EK (default) | 0.744 | 7 | EK (default) | 0.744 |
| 8 | MAIVE (WAIVE) | 0.724 | 8 | MAIVE (WAIVE) | 0.724 |
| 9 | PETPEESE (default) | 0.718 | 9 | PETPEESE (default) | 0.718 |
| 10 | PET (default) | 0.716 | 10 | PET (default) | 0.716 |
| 11 | AK (AK1) | 0.666 | 11 | AK (AK1) | 0.665 |
| 12 | PEESE (default) | 0.573 | 12 | PEESE (default) | 0.573 |
| 13 | WAAPWLS (default) | 0.571 | 13 | WAAPWLS (default) | 0.571 |
| 14 | trimfill (default) | 0.550 | 14 | trimfill (default) | 0.550 |
| 15 | RMA (default) | 0.546 | 15 | RMA (default) | 0.546 |
| 16 | WLS (default) | 0.537 | 16 | WLS (default) | 0.537 |
| 17 | puniform (default) | 0.531 | 17 | puniform (default) | 0.532 |
| 18 | WILS (default) | 0.524 | 18 | WILS (default) | 0.524 |
| 19 | FMA (default) | 0.414 | 19 | FMA (default) | 0.414 |
| 20 | mean (default) | 0.376 | 20 | mean (default) | 0.376 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
95% CI coverage is the proportion of simulation runs in which the 95% confidence interval contained the true effect. Ideally, this value should be close to the nominal level of 95%.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | FMA (default) | 0.079 | 1 | FMA (default) | 0.079 |
| 2 | mean (default) | 0.105 | 2 | mean (default) | 0.105 |
| 3 | WILS (default) | 0.130 | 3 | WILS (default) | 0.130 |
| 4 | WLS (default) | 0.134 | 4 | WLS (default) | 0.134 |
| 5 | WAAPWLS (default) | 0.149 | 5 | WAAPWLS (default) | 0.149 |
| 6 | trimfill (default) | 0.167 | 6 | trimfill (default) | 0.167 |
| 7 | PEESE (default) | 0.171 | 7 | PEESE (default) | 0.171 |
| 8 | RMA (default) | 0.173 | 8 | RMA (default) | 0.173 |
| 9 | RoBMA (PSMA) | 0.191 | 9 | RoBMA (PSMA) | 0.191 |
| 10 | PETPEESE (default) | 0.235 | 10 | PETPEESE (default) | 0.235 |
| 11 | AK (AK2) | 0.255 | 11 | puniform (star) | 0.278 |
| 12 | puniform (star) | 0.278 | 12 | PET (default) | 0.300 |
| 13 | PET (default) | 0.300 | 13 | SM (3PSM) | 0.321 |
| 14 | MAIVE (default) | 0.360 | 14 | MAIVE (default) | 0.360 |
| 15 | SM (3PSM) | 0.366 | 15 | EK (default) | 0.367 |
| 16 | EK (default) | 0.367 | 16 | MAIVE (WAIVE) | 0.451 |
| 17 | MAIVE (WAIVE) | 0.451 | 17 | puniform (default) | 0.453 |
| 18 | puniform (default) | 0.588 | 18 | AK (AK2) | 0.464 |
| 19 | SM (4PSM) | 0.992 | 19 | SM (4PSM) | 0.655 |
| 20 | AK (AK1) | 1.982 | 20 | AK (AK1) | 1.781 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
95% CI width is the average length of the 95% confidence interval for the true effect. A lower average 95% CI length indicates a better method.
| Rank | Method | Log Value | Rank | Method | Log Value |
|---|---|---|---|---|---|
| 1 | RoBMA (PSMA) | 5.324 | 1 | RoBMA (PSMA) | 5.324 |
| 2 | AK (AK2) | 3.027 | 2 | AK (AK2) | 2.486 |
| 3 | SM (4PSM) | 2.431 | 3 | SM (4PSM) | 2.441 |
| 4 | MAIVE (WAIVE) | 2.388 | 4 | MAIVE (WAIVE) | 2.388 |
| 5 | puniform (star) | 2.007 | 5 | puniform (star) | 2.007 |
| 6 | MAIVE (default) | 1.911 | 6 | MAIVE (default) | 1.911 |
| 7 | SM (3PSM) | 1.871 | 7 | SM (3PSM) | 1.852 |
| 8 | PET (default) | 1.818 | 8 | PET (default) | 1.818 |
| 9 | EK (default) | 1.818 | 9 | EK (default) | 1.818 |
| 10 | PETPEESE (default) | 1.677 | 10 | PETPEESE (default) | 1.677 |
| 11 | AK (AK1) | 1.339 | 11 | AK (AK1) | 1.313 |
| 12 | WILS (default) | 1.130 | 12 | WILS (default) | 1.130 |
| 13 | RMA (default) | 1.060 | 13 | RMA (default) | 1.060 |
| 14 | PEESE (default) | 0.977 | 14 | PEESE (default) | 0.977 |
| 15 | puniform (default) | 0.962 | 15 | puniform (default) | 0.966 |
| 16 | WAAPWLS (default) | 0.946 | 16 | WAAPWLS (default) | 0.946 |
| 17 | WLS (default) | 0.882 | 17 | WLS (default) | 0.882 |
| 18 | trimfill (default) | 0.825 | 18 | trimfill (default) | 0.825 |
| 19 | mean (default) | 0.651 | 19 | mean (default) | 0.651 |
| 20 | FMA (default) | 0.566 | 20 | FMA (default) | 0.566 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
The positive likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a positive likelihood ratio greater than 1 (or a log positive likelihood ratio greater than 0). A higher (log) positive likelihood ratio indicates a better method.
| Rank | Method | Log Value | Rank | Method | Log Value |
|---|---|---|---|---|---|
| 1 | RoBMA (PSMA) | -5.344 | 1 | AK (AK2) | -6.371 |
| 2 | MAIVE (default) | -5.046 | 2 | RoBMA (PSMA) | -5.344 |
| 3 | PETPEESE (default) | -5.031 | 3 | SM (4PSM) | -5.289 |
| 4 | AK (AK2) | -4.939 | 4 | MAIVE (default) | -5.046 |
| 5 | PET (default) | -4.925 | 5 | PETPEESE (default) | -5.031 |
| 6 | EK (default) | -4.925 | 6 | SM (3PSM) | -4.949 |
| 7 | SM (3PSM) | -4.896 | 7 | PET (default) | -4.925 |
| 8 | SM (4PSM) | -4.804 | 8 | EK (default) | -4.925 |
| 9 | puniform (star) | -4.121 | 9 | puniform (star) | -4.121 |
| 10 | puniform (default) | -3.885 | 10 | puniform (default) | -3.892 |
| 11 | PEESE (default) | -3.691 | 11 | PEESE (default) | -3.691 |
| 12 | WAAPWLS (default) | -3.494 | 12 | WAAPWLS (default) | -3.494 |
| 13 | trimfill (default) | -3.454 | 13 | trimfill (default) | -3.454 |
| 14 | AK (AK1) | -3.453 | 14 | AK (AK1) | -3.453 |
| 15 | WLS (default) | -3.274 | 15 | WLS (default) | -3.274 |
| 16 | WILS (default) | -3.233 | 16 | WILS (default) | -3.233 |
| 17 | RMA (default) | -3.200 | 17 | RMA (default) | -3.200 |
| 18 | FMA (default) | -3.049 | 18 | FMA (default) | -3.049 |
| 19 | mean (default) | -3.038 | 19 | mean (default) | -3.038 |
| 20 | MAIVE (WAIVE) | -2.985 | 20 | MAIVE (WAIVE) | -2.985 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
The negative likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a non-significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a negative likelihood ratio less than 1 (or a log negative likelihood ratio less than 0). A lower (log) negative likelihood ratio indicates a better method.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | RoBMA (PSMA) | 0.025 | 1 | RoBMA (PSMA) | 0.025 |
| 2 | AK (AK2) | 0.073 | 2 | SM (4PSM) | 0.109 |
| 3 | SM (4PSM) | 0.095 | 3 | MAIVE (WAIVE) | 0.115 |
| 4 | MAIVE (WAIVE) | 0.115 | 4 | AK (AK2) | 0.136 |
| 5 | PET (default) | 0.259 | 5 | PET (default) | 0.259 |
| 6 | EK (default) | 0.259 | 6 | EK (default) | 0.259 |
| 7 | MAIVE (default) | 0.259 | 7 | MAIVE (default) | 0.259 |
| 8 | puniform (star) | 0.268 | 8 | puniform (star) | 0.268 |
| 9 | PETPEESE (default) | 0.296 | 9 | PETPEESE (default) | 0.296 |
| 10 | SM (3PSM) | 0.308 | 10 | SM (3PSM) | 0.314 |
| 11 | WILS (default) | 0.410 | 11 | WILS (default) | 0.410 |
| 12 | PEESE (default) | 0.568 | 12 | PEESE (default) | 0.568 |
| 13 | AK (AK1) | 0.579 | 13 | AK (AK1) | 0.579 |
| 14 | WAAPWLS (default) | 0.590 | 14 | WAAPWLS (default) | 0.590 |
| 15 | puniform (default) | 0.615 | 15 | puniform (default) | 0.612 |
| 16 | RMA (default) | 0.623 | 16 | RMA (default) | 0.623 |
| 17 | WLS (default) | 0.634 | 17 | WLS (default) | 0.634 |
| 18 | trimfill (default) | 0.638 | 18 | trimfill (default) | 0.638 |
| 19 | mean (default) | 0.723 | 19 | mean (default) | 0.723 |
| 20 | FMA (default) | 0.753 | 20 | FMA (default) | 0.753 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
The type I error rate is the proportion of simulation runs in which the null hypothesis of no effect was incorrectly rejected when it was true. Ideally, this value should be close to the nominal level of 5%.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | mean (default) | 0.999 | 1 | mean (default) | 0.999 |
| 2 | FMA (default) | 0.999 | 2 | FMA (default) | 0.999 |
| 3 | puniform (default) | 0.997 | 3 | puniform (default) | 0.997 |
| 4 | AK (AK1) | 0.990 | 4 | AK (AK1) | 0.990 |
| 5 | WLS (default) | 0.989 | 5 | WLS (default) | 0.989 |
| 6 | RMA (default) | 0.989 | 6 | RMA (default) | 0.989 |
| 7 | trimfill (default) | 0.988 | 7 | trimfill (default) | 0.988 |
| 8 | WAAPWLS (default) | 0.972 | 8 | AK (AK2) | 0.983 |
| 9 | PEESE (default) | 0.969 | 9 | WAAPWLS (default) | 0.972 |
| 10 | AK (AK2) | 0.968 | 10 | PEESE (default) | 0.969 |
| 11 | SM (3PSM) | 0.960 | 11 | SM (3PSM) | 0.965 |
| 12 | MAIVE (default) | 0.945 | 12 | MAIVE (default) | 0.945 |
| 13 | PETPEESE (default) | 0.931 | 13 | SM (4PSM) | 0.938 |
| 14 | EK (default) | 0.905 | 14 | PETPEESE (default) | 0.931 |
| 14 | PET (default) | 0.905 | 15 | EK (default) | 0.905 |
| 16 | SM (4PSM) | 0.903 | 15 | PET (default) | 0.905 |
| 17 | WILS (default) | 0.901 | 17 | WILS (default) | 0.901 |
| 18 | RoBMA (PSMA) | 0.898 | 18 | RoBMA (PSMA) | 0.898 |
| 19 | puniform (star) | 0.886 | 19 | puniform (star) | 0.886 |
| 20 | MAIVE (WAIVE) | 0.767 | 20 | MAIVE (WAIVE) | 0.767 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
The power is the proportion of simulation runs in which the null hypothesis of no effect was correctly rejected when the alternative hypothesis was true. A higher power indicates a better method.
By-Condition Performance (Conditional on Method Convergence)
The results below are conditional on method convergence. Note that the methods might differ in convergence rate and are therefore not compared on the same data sets.
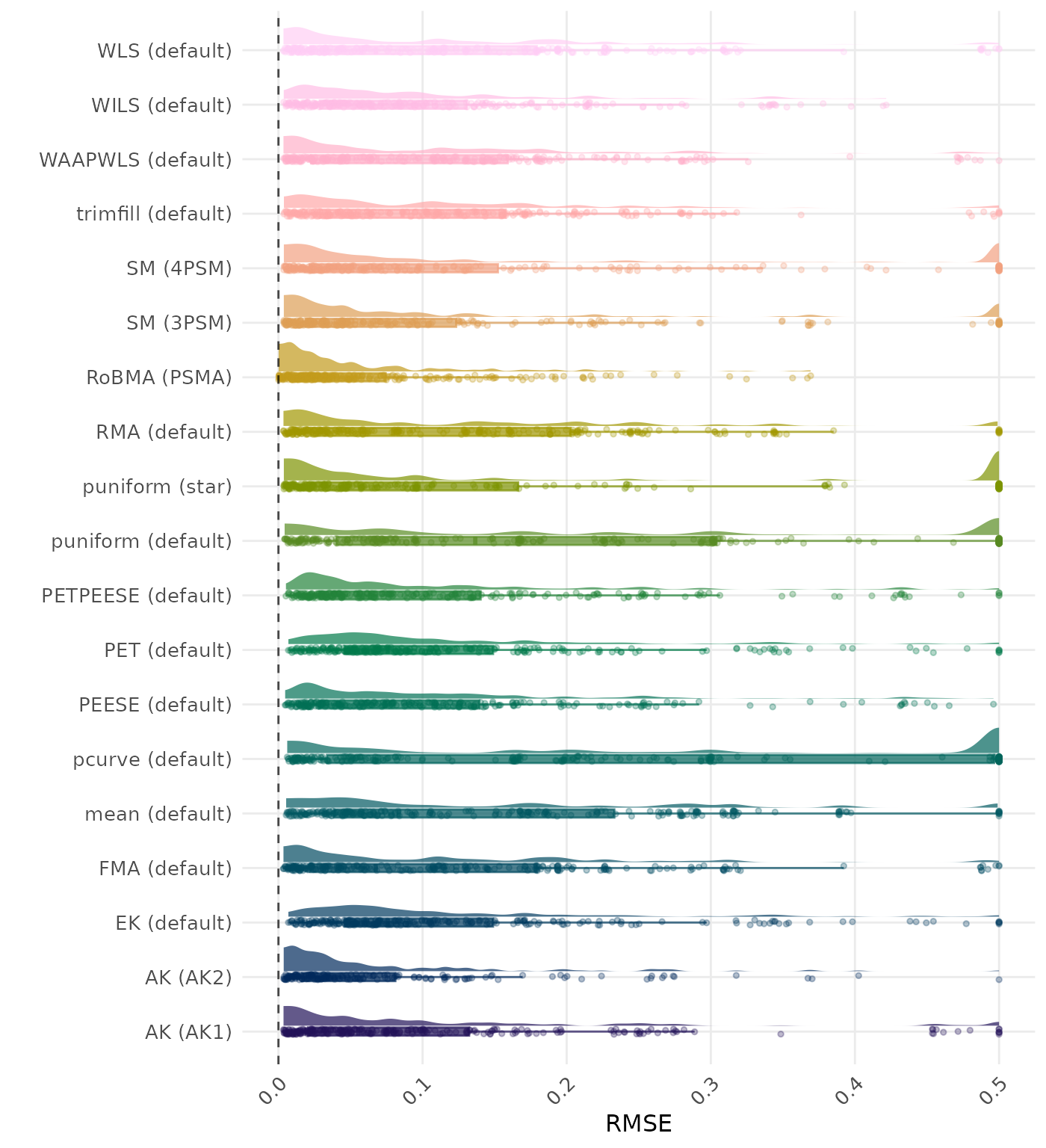
RMSE (Root Mean Square Error) is an overall summary measure of estimation performance that combines bias and empirical SE. RMSE is the square root of the average squared difference between the meta-analytic estimate and the true effect across simulation runs. A lower RMSE indicates a better method. Values larger than 0.5 are visualized as 0.5.
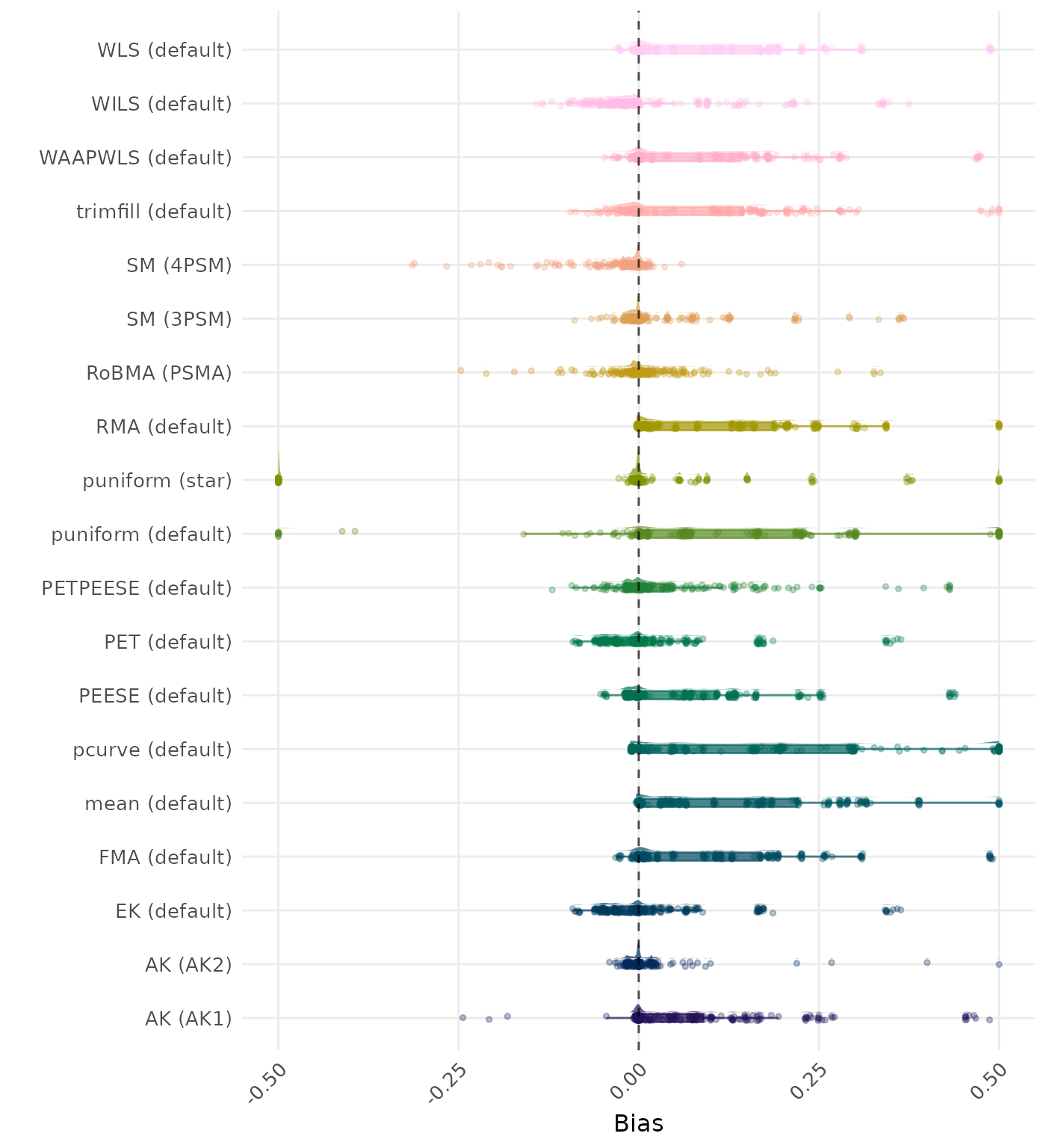
Bias is the average difference between the meta-analytic estimate and the true effect across simulation runs. Ideally, this value should be close to 0. Values lower than -0.5 or larger than 0.5 are visualized as -0.5 and 0.5 respectively.
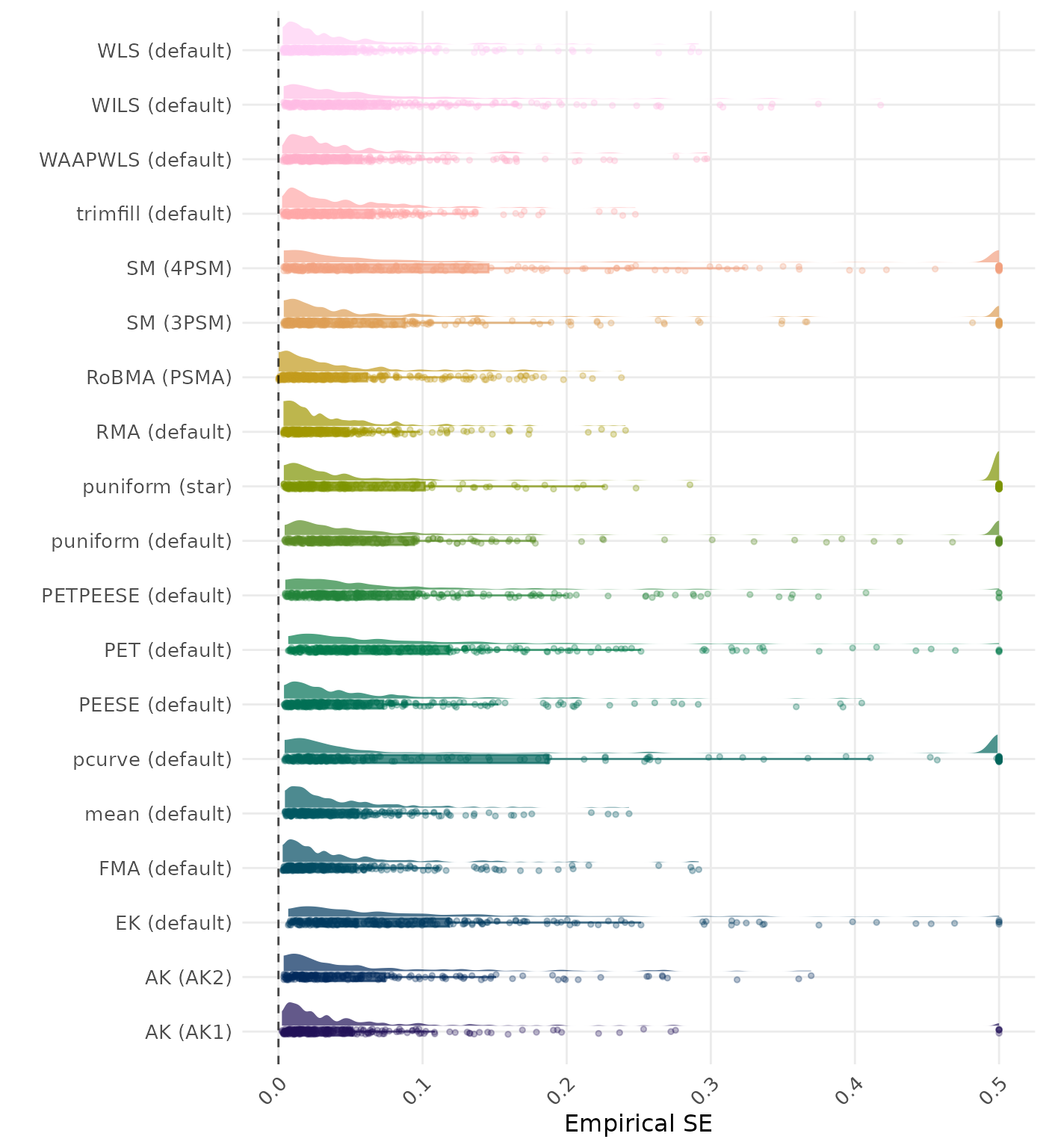
The empirical SE is the standard deviation of the meta-analytic estimate across simulation runs. A lower empirical SE indicates less variability and better method performance. Values larger than 0.5 are visualized as 0.5.
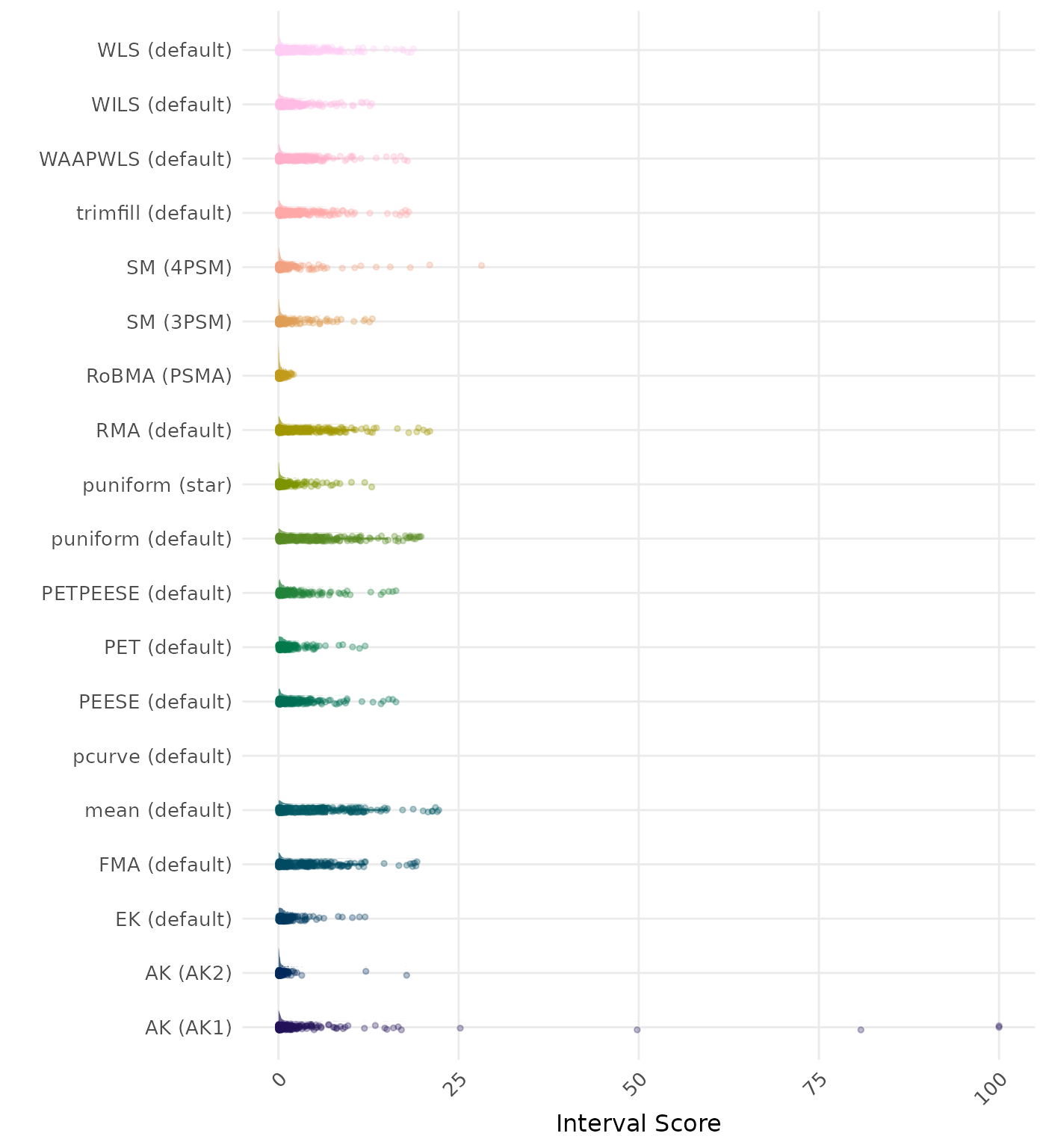
The interval score measures the accuracy of a confidence interval by combining its width and coverage. It penalizes intervals that are too wide or that fail to include the true value. A lower interval score indicates a better method. Values larger than 100 are visualized as 100.
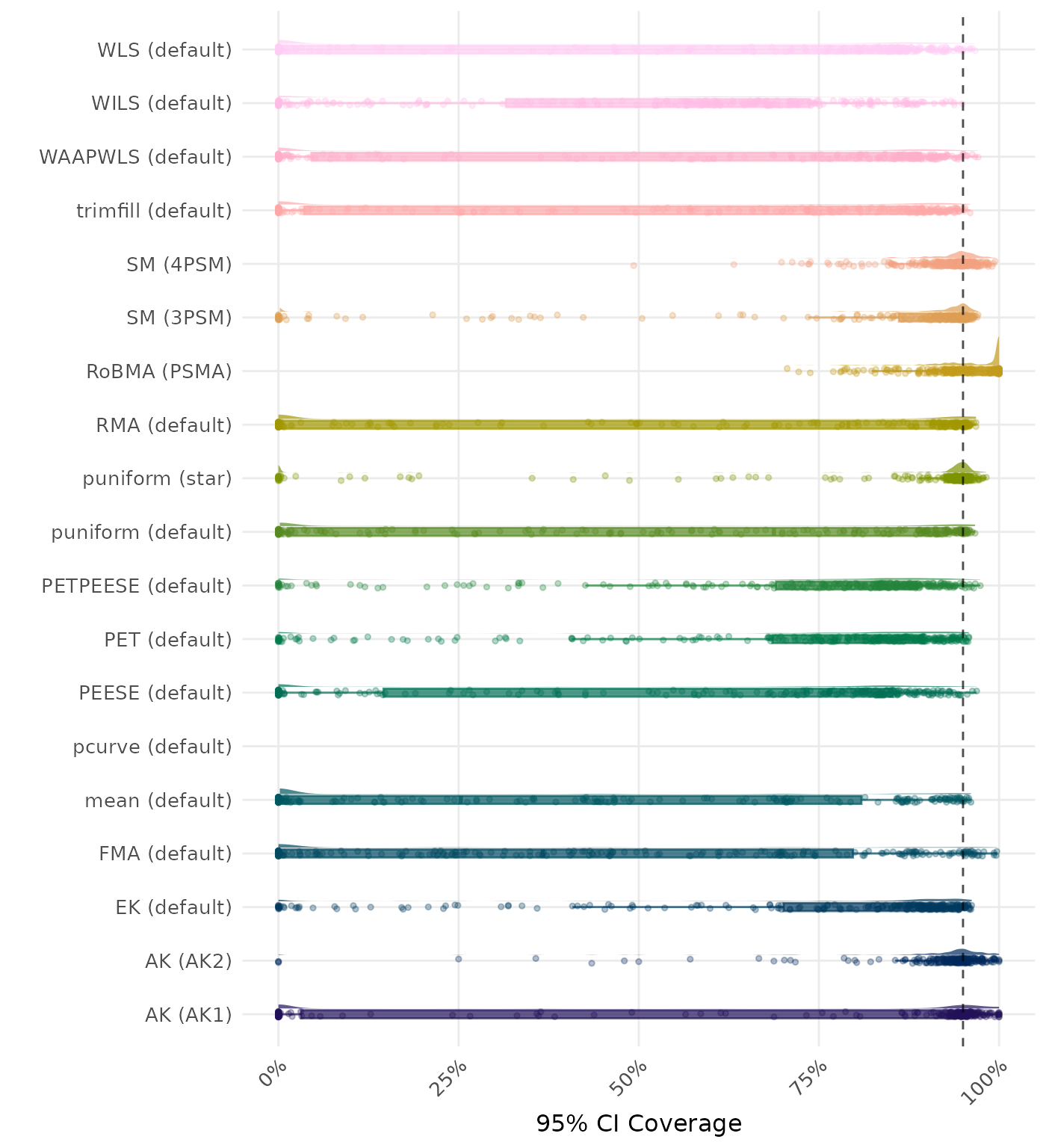
95% CI coverage is the proportion of simulation runs in which the 95% confidence interval contained the true effect. Ideally, this value should be close to the nominal level of 95%.
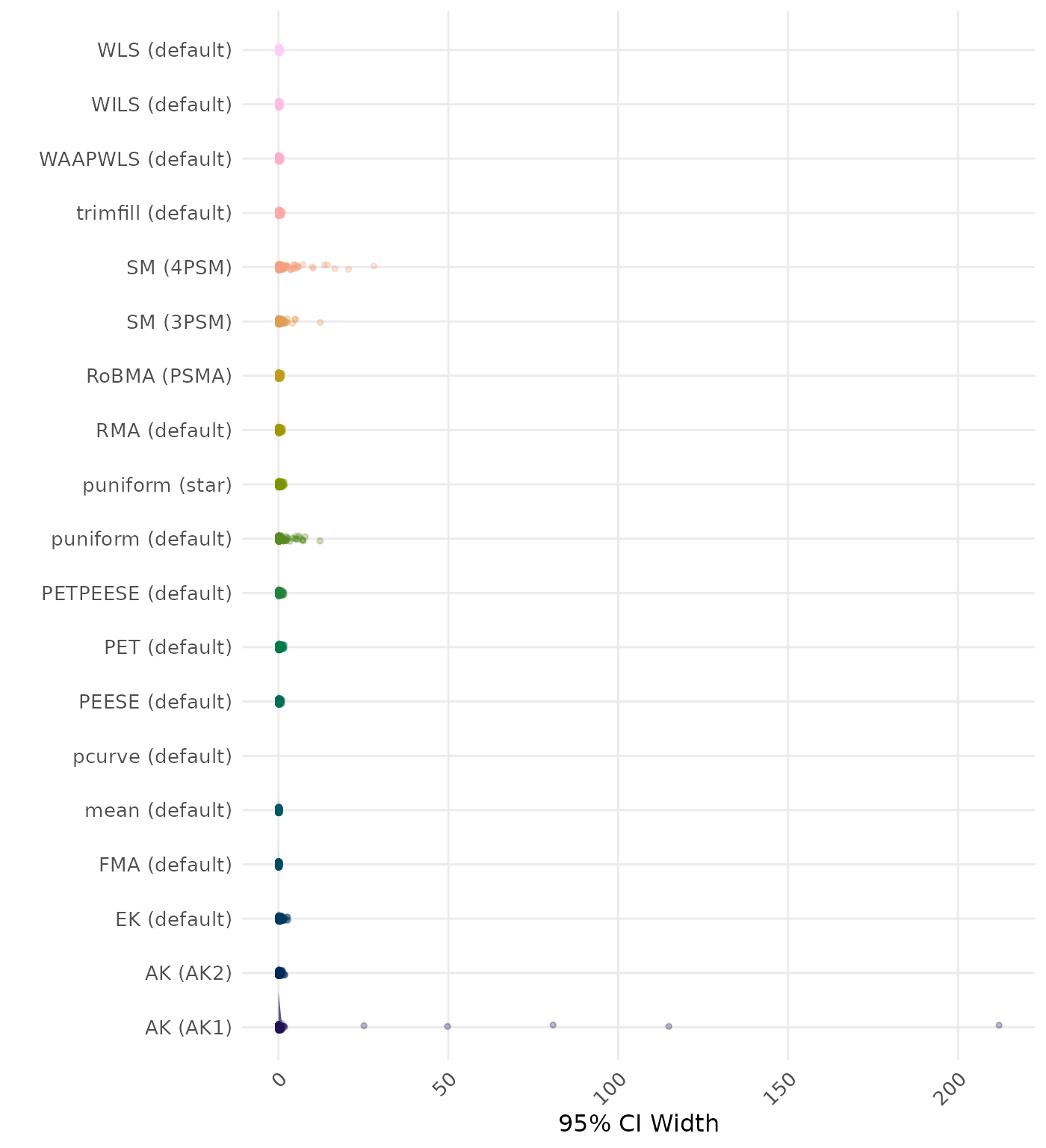
95% CI width is the average length of the 95% confidence interval for the true effect. A lower average 95% CI length indicates a better method.
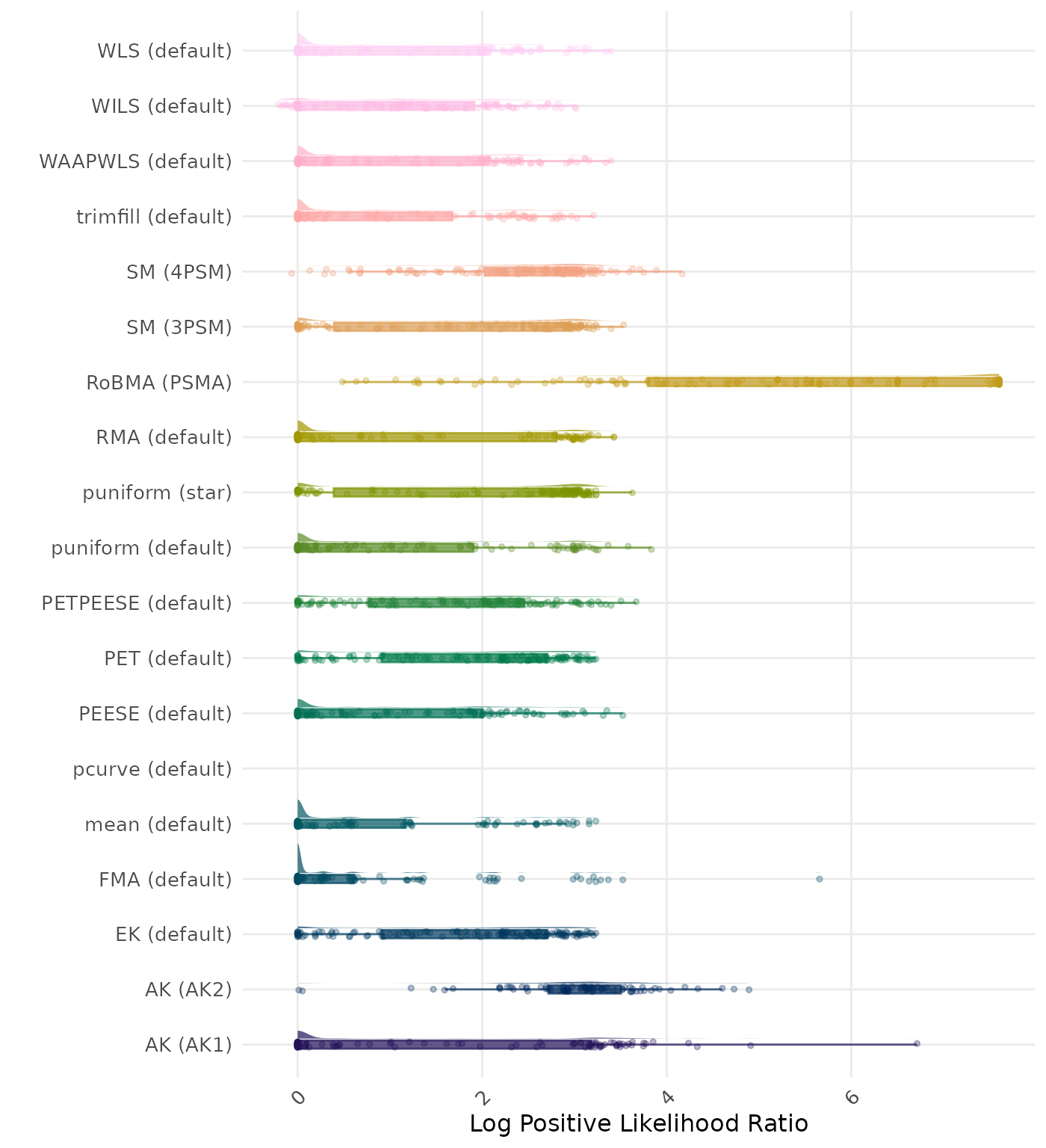
The positive likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a positive likelihood ratio greater than 1 (or a log positive likelihood ratio greater than 0). A higher (log) positive likelihood ratio indicates a better method.
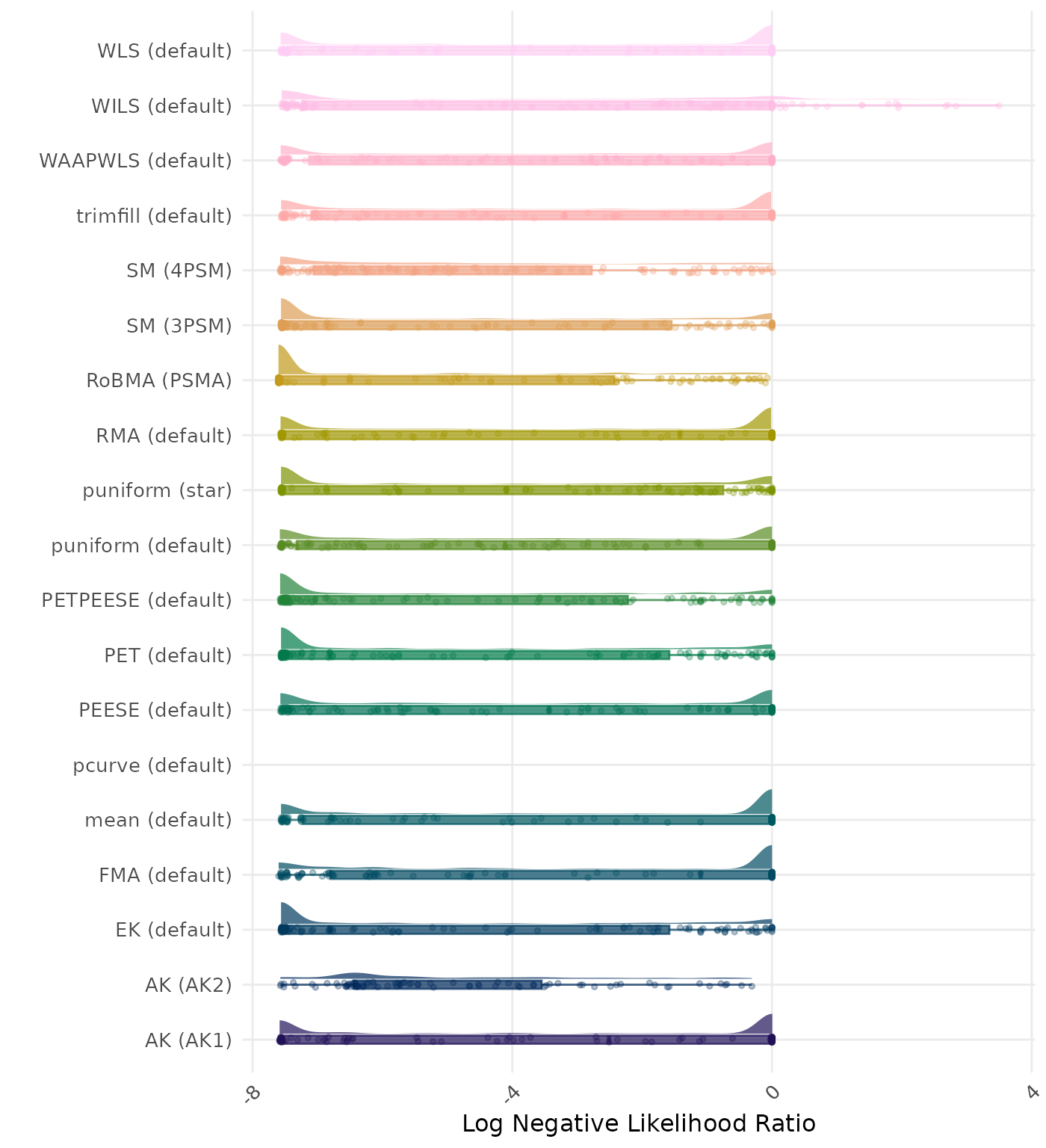
The negative likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a non-significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a negative likelihood ratio less than 1 (or a log negative likelihood ratio less than 0). A lower (log) negative likelihood ratio indicates a better method.
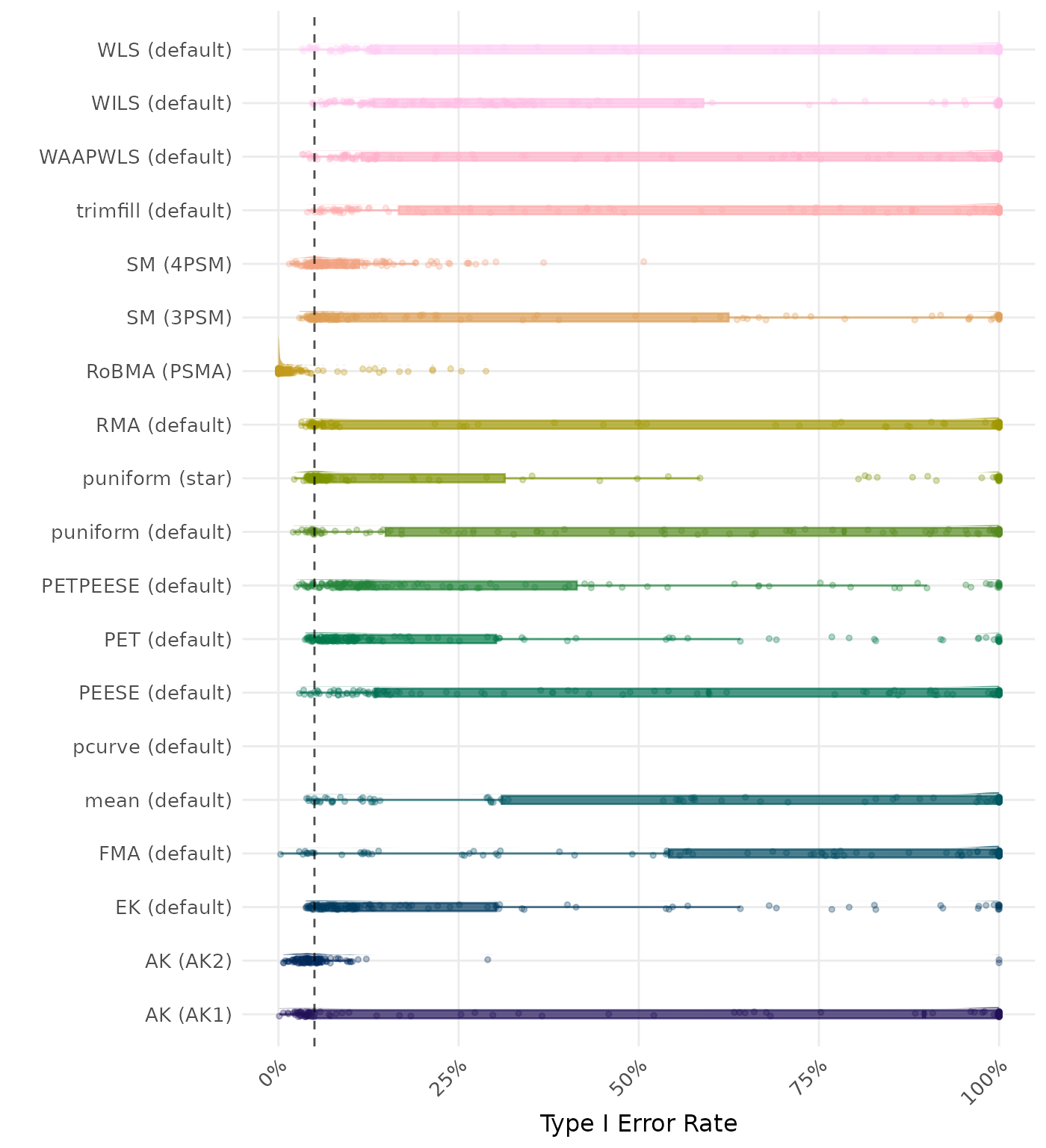
The type I error rate is the proportion of simulation runs in which the null hypothesis of no effect was incorrectly rejected when it was true. Ideally, this value should be close to the nominal level of 5%.
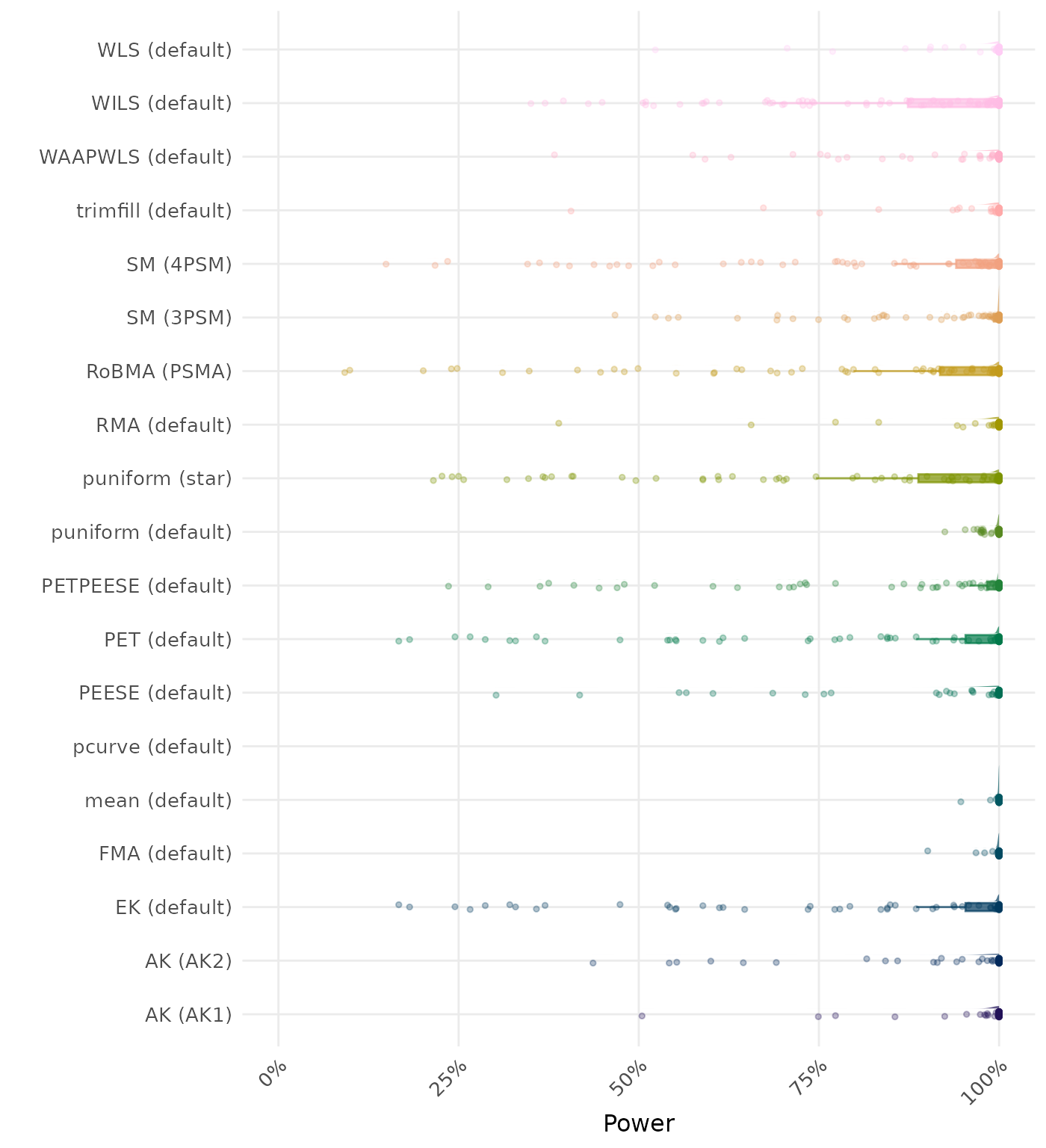
The power is the proportion of simulation runs in which the null hypothesis of no effect was correctly rejected when the alternative hypothesis was true. A higher power indicates a better method.
By-Condition Performance (Replacement in Case of Non-Convergence)
The results below incorporate method replacement to handle non-convergence. If a method fails to converge, its results are replaced with the results from a simpler method (e.g., random-effects meta-analysis without publication bias adjustment). This emulates what a data analyst may do in practice in case a method does not converge. However, note that these results do not correspond to “pure” method performance as they might combine multiple different methods. See Method Replacement Strategy for details of the method replacement specification.
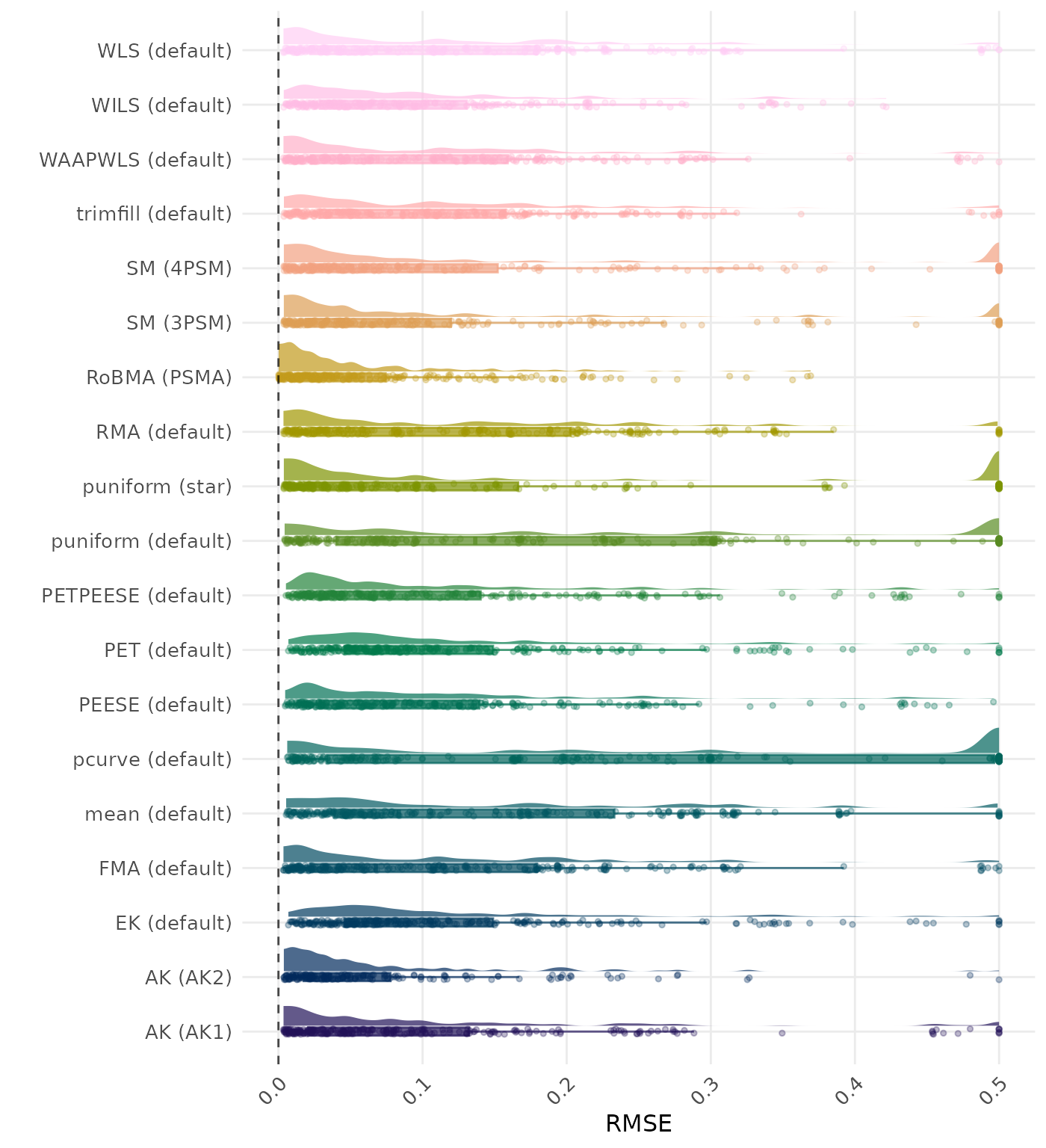
RMSE (Root Mean Square Error) is an overall summary measure of estimation performance that combines bias and empirical SE. RMSE is the square root of the average squared difference between the meta-analytic estimate and the true effect across simulation runs. A lower RMSE indicates a better method. Values larger than 0.5 are visualized as 0.5.
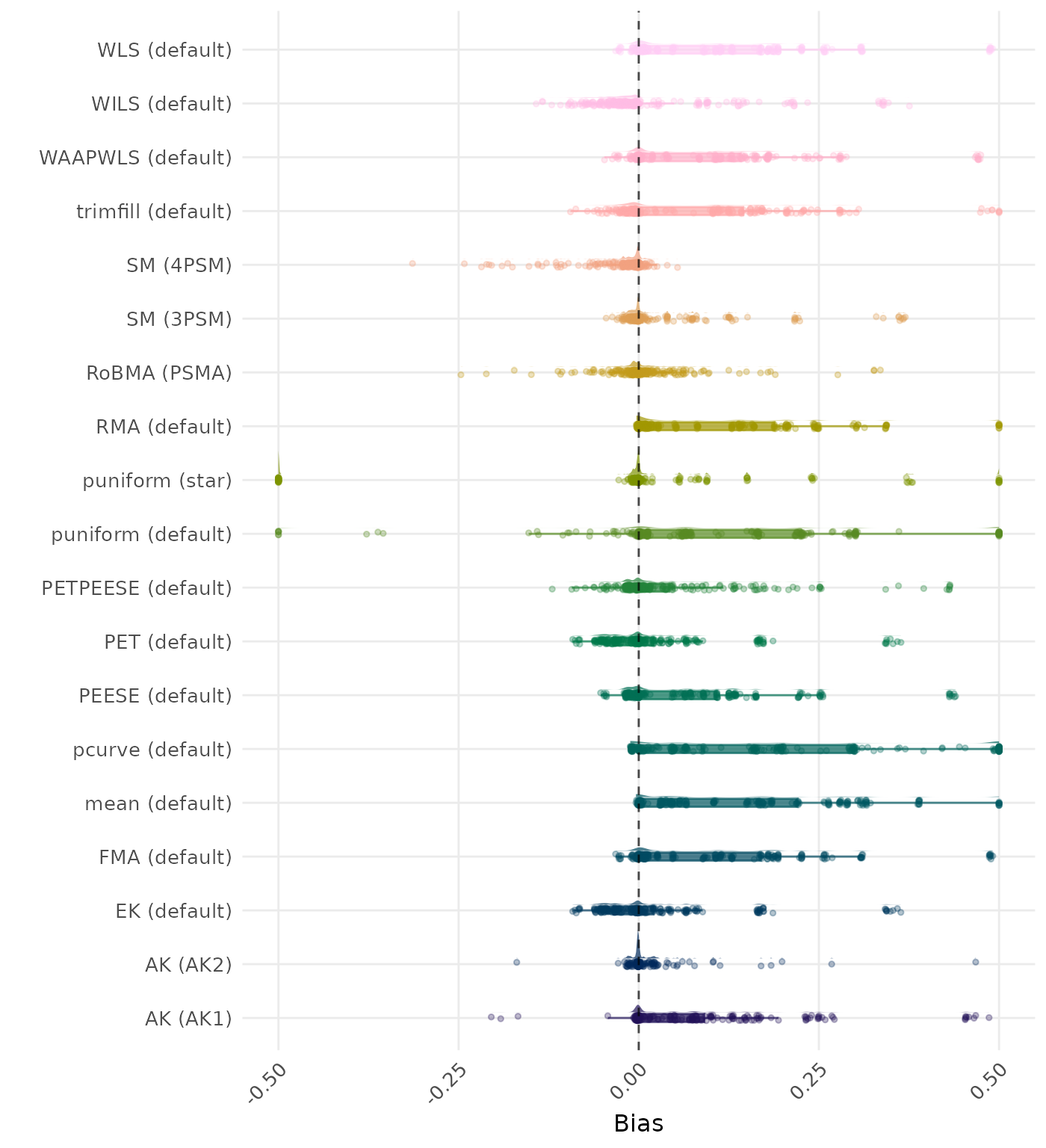
Bias is the average difference between the meta-analytic estimate and the true effect across simulation runs. Ideally, this value should be close to 0. Values lower than -0.5 or larger than 0.5 are visualized as -0.5 and 0.5 respectively.
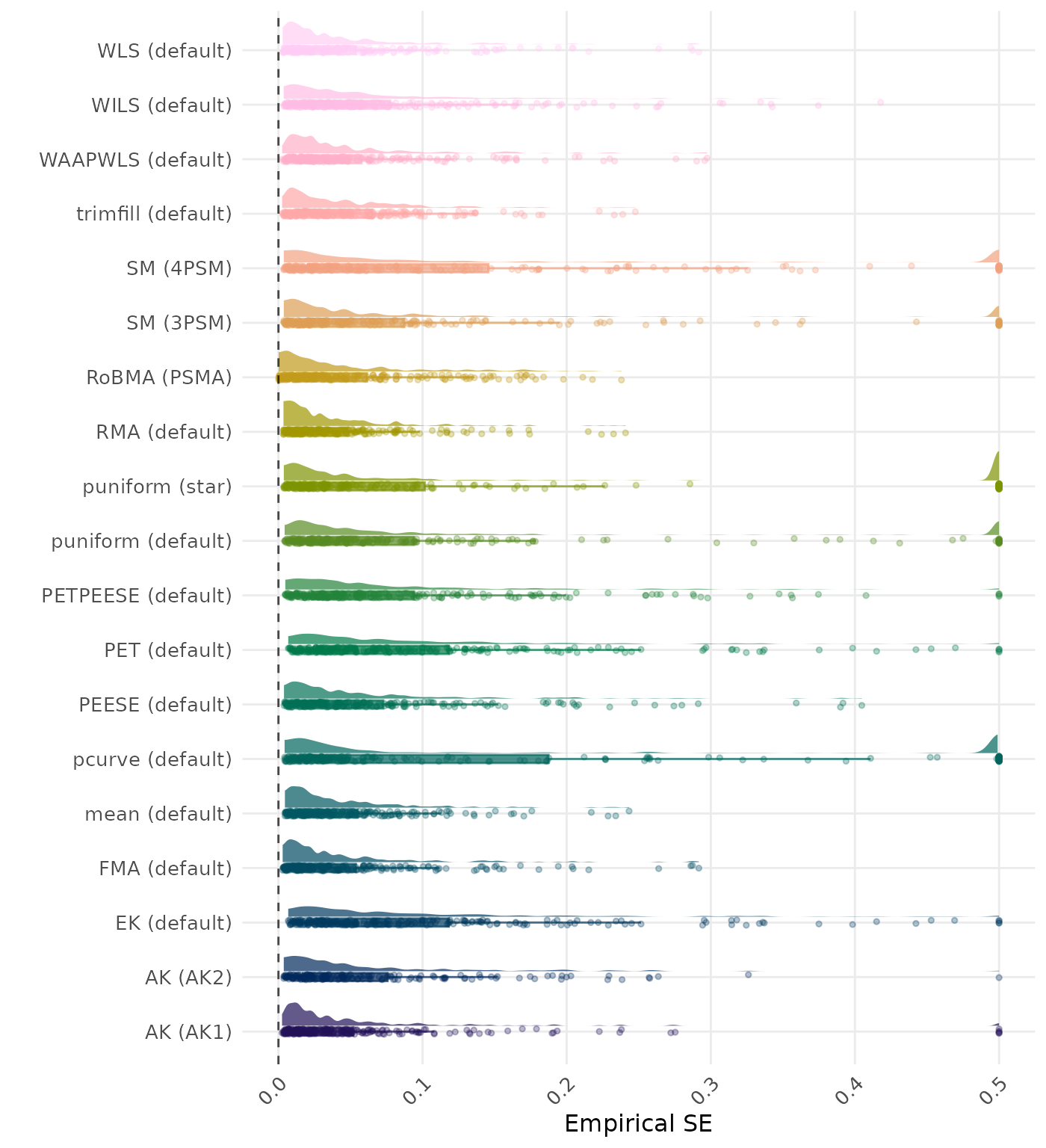
The empirical SE is the standard deviation of the meta-analytic estimate across simulation runs. A lower empirical SE indicates less variability and better method performance. Values larger than 0.5 are visualized as 0.5.
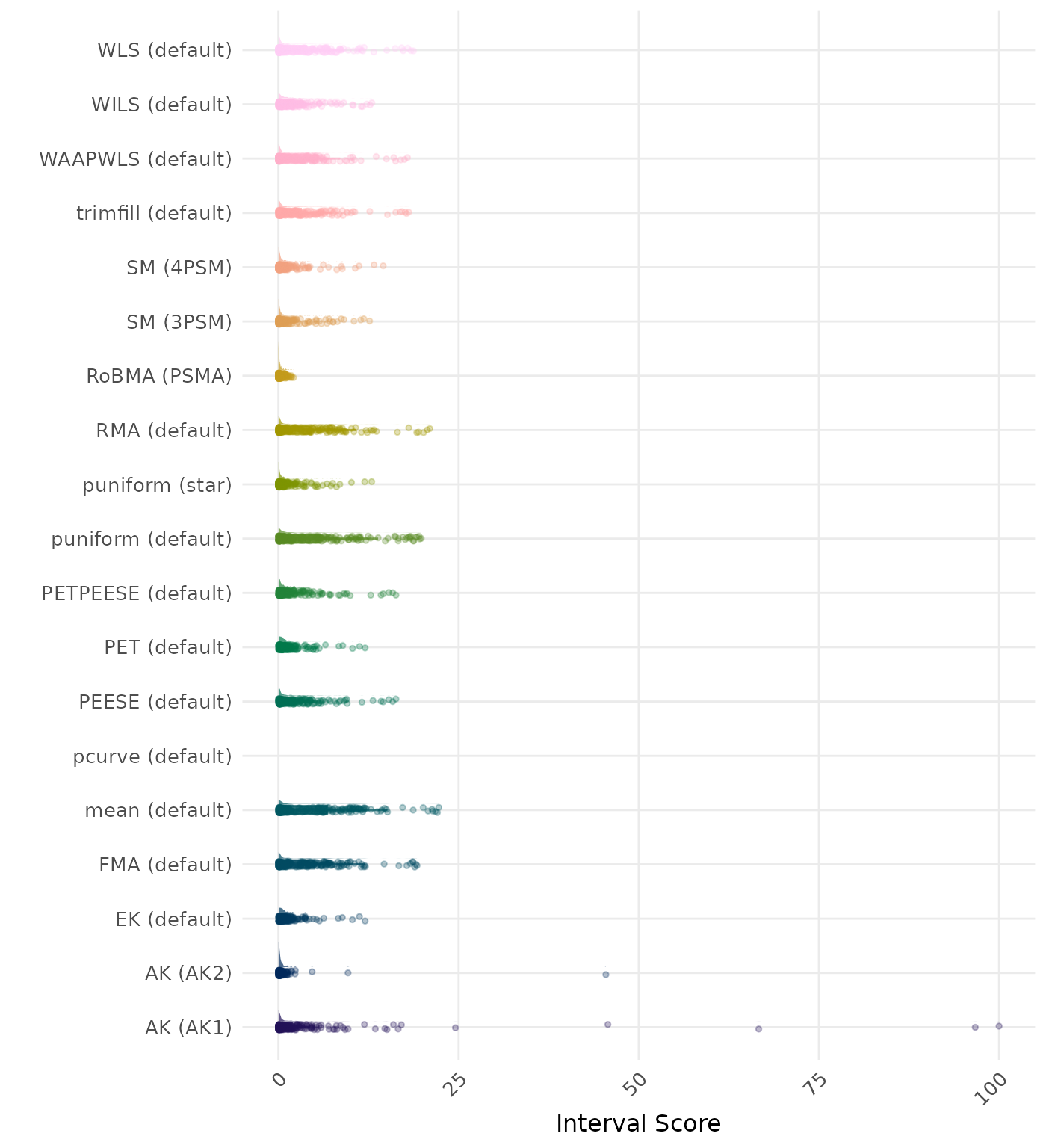
The interval score measures the accuracy of a confidence interval by combining its width and coverage. It penalizes intervals that are too wide or that fail to include the true value. A lower interval score indicates a better method. Values larger than 100 are visualized as 100.
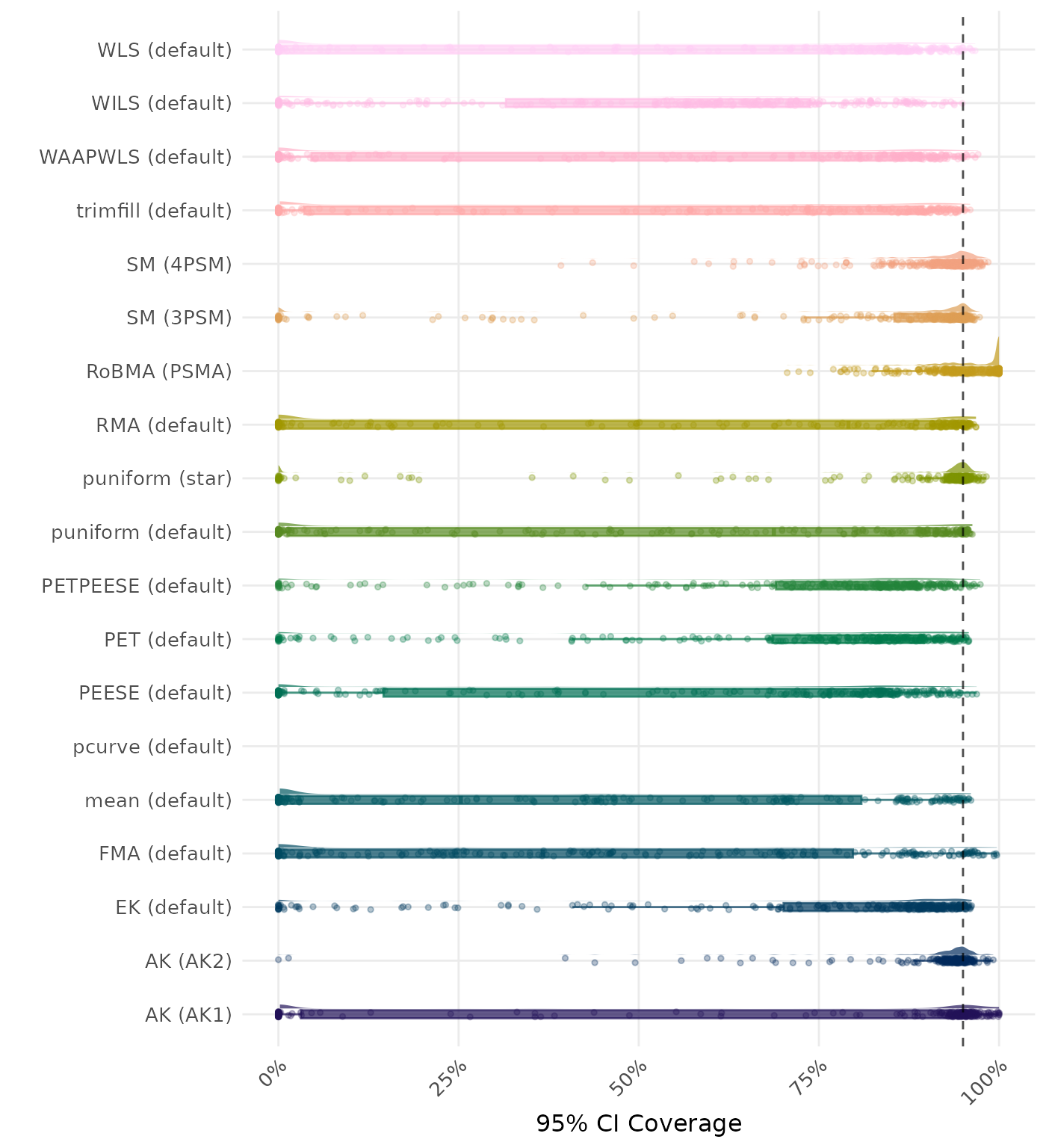
95% CI coverage is the proportion of simulation runs in which the 95% confidence interval contained the true effect. Ideally, this value should be close to the nominal level of 95%.
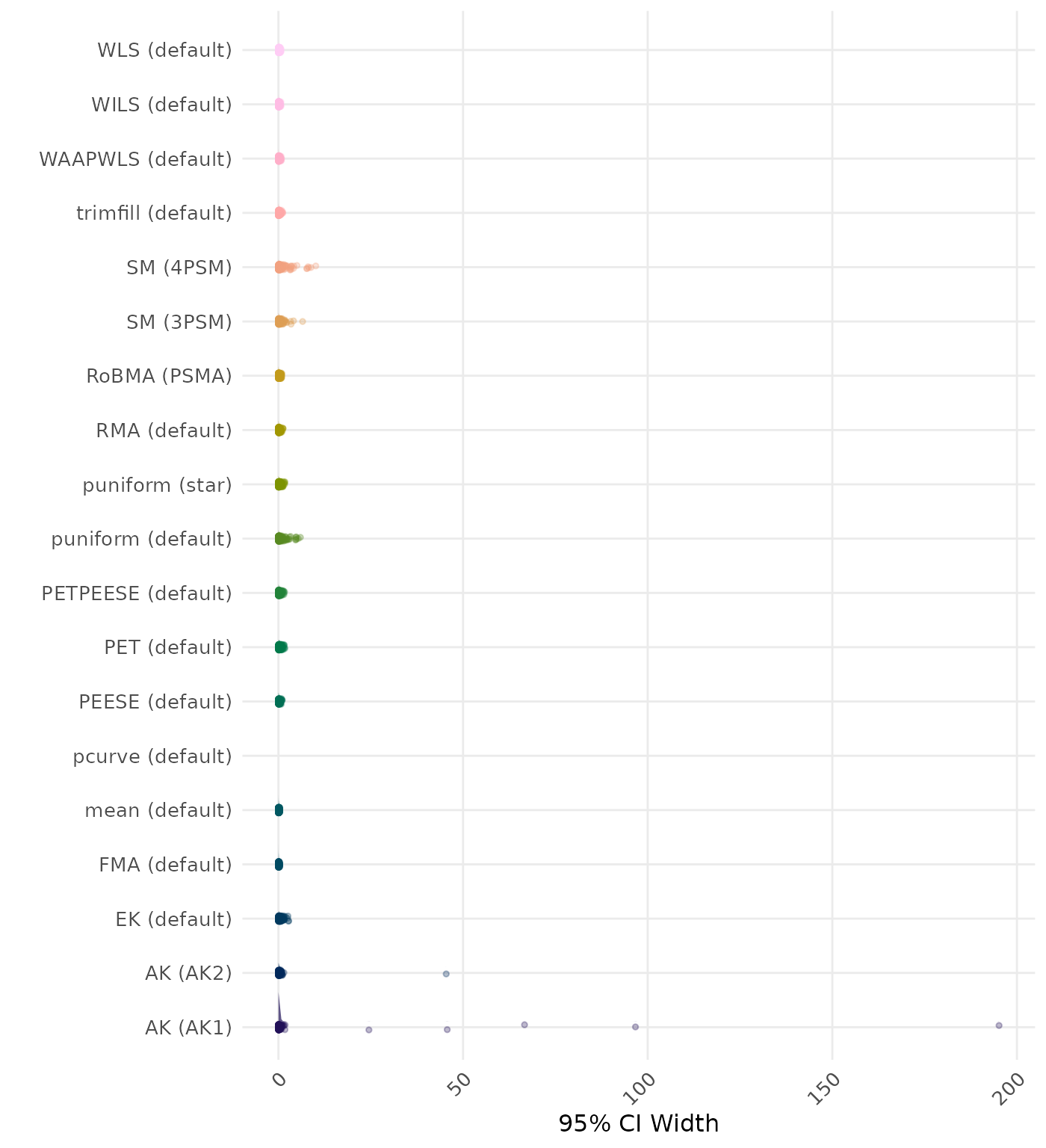
95% CI width is the average length of the 95% confidence interval for the true effect. A lower average 95% CI length indicates a better method.
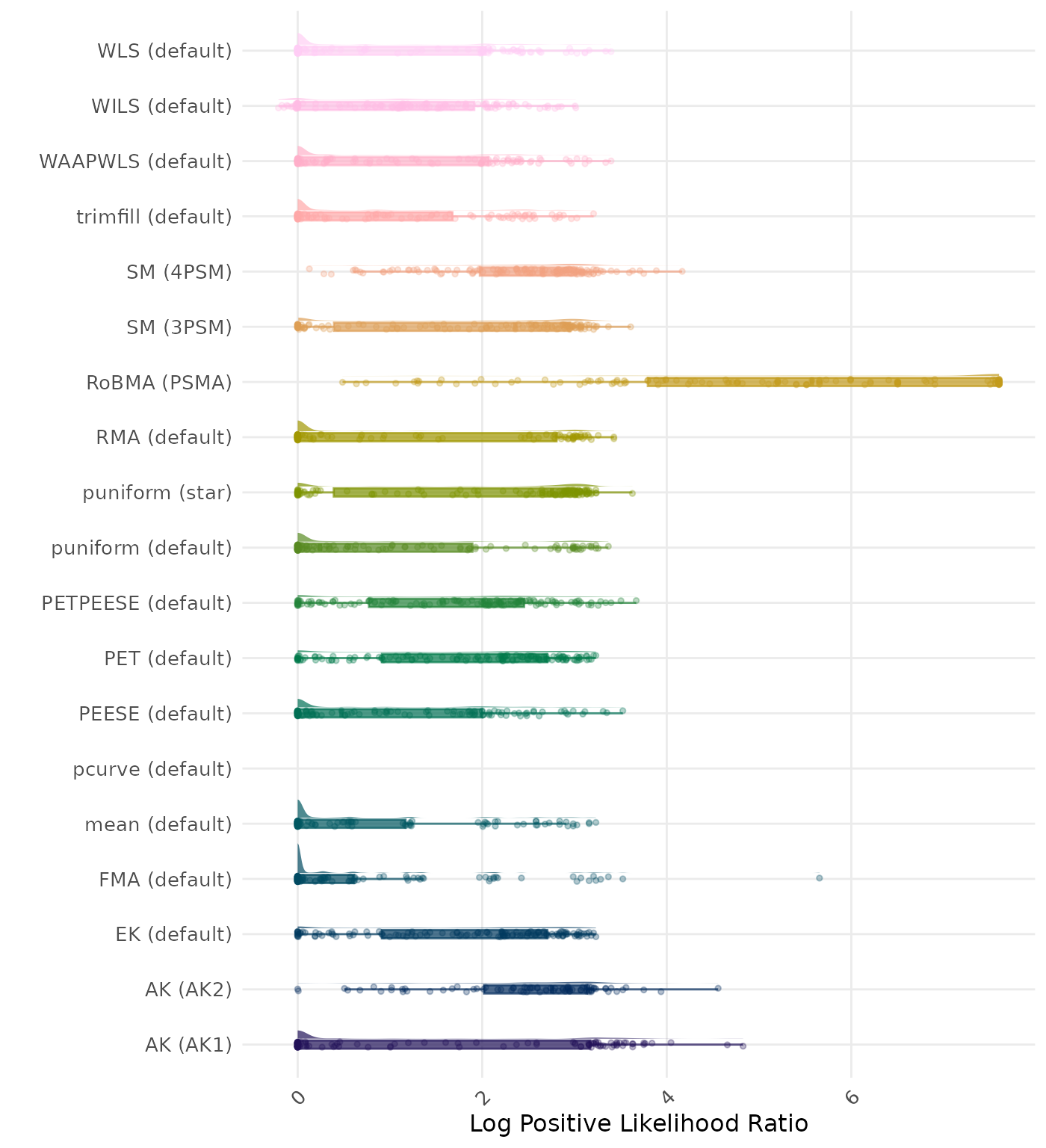
The positive likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a positive likelihood ratio greater than 1 (or a log positive likelihood ratio greater than 0). A higher (log) positive likelihood ratio indicates a better method.
The negative likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a non-significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a negative likelihood ratio less than 1 (or a log negative likelihood ratio less than 0). A lower (log) negative likelihood ratio indicates a better method.
The type I error rate is the proportion of simulation runs in which the null hypothesis of no effect was incorrectly rejected when it was true. Ideally, this value should be close to the nominal level of 5%.
The power is the proportion of simulation runs in which the null hypothesis of no effect was correctly rejected when the alternative hypothesis was true. A higher power indicates a better method.
Subset: Log Odd Ratio Effect Sizes
These results are based on Stanley (2017) data-generating mechanism with a total of 1 conditions.
Average Performance
Method performance measures are aggregated across all simulated conditions to provide an overall impression of method performance. However, keep in mind that a method with a high overall ranking is not necessarily the “best” method for a particular application. To select a suitable method for your application, consider also non-aggregated performance measures in conditions most relevant to your application.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | RoBMA (PSMA) | 0.206 | 1 | RoBMA (PSMA) | 0.238 |
| 2 | EK (default) | 0.263 | 2 | EK (default) | 0.263 |
| 3 | PET (default) | 0.264 | 3 | PET (default) | 0.264 |
| 4 | AK (AK2) | 0.265 | 4 | SM (3PSM) | 0.273 |
| 5 | WILS (default) | 0.274 | 5 | WILS (default) | 0.274 |
| 6 | SM (3PSM) | 0.274 | 6 | PETPEESE (default) | 0.297 |
| 7 | PETPEESE (default) | 0.297 | 7 | SM (4PSM) | 0.308 |
| 8 | PEESE (default) | 0.313 | 8 | PEESE (default) | 0.313 |
| 9 | SM (4PSM) | 0.316 | 9 | MAIVE (default) | 0.337 |
| 10 | MAIVE (default) | 0.337 | 10 | trimfill (default) | 0.348 |
| 11 | trimfill (default) | 0.348 | 11 | WAAPWLS (default) | 0.352 |
| 12 | WAAPWLS (default) | 0.352 | 12 | FMA (default) | 0.372 |
| 13 | FMA (default) | 0.372 | 13 | WLS (default) | 0.372 |
| 14 | WLS (default) | 0.372 | 14 | RMA (default) | 0.391 |
| 15 | RMA (default) | 0.391 | 15 | MAIVE (WAIVE) | 0.420 |
| 16 | MAIVE (WAIVE) | 0.420 | 16 | mean (default) | 0.501 |
| 17 | mean (default) | 0.501 | 17 | AK (AK2) | 1.061 |
| 18 | pcurve (default) | 1.293 | 18 | pcurve (default) | 1.127 |
| 19 | AK (AK1) | 1.581 | 19 | puniform (default) | 1.339 |
| 20 | puniform (default) | 1.713 | 20 | AK (AK1) | 1.429 |
| 21 | puniform (star) | 157.696 | 21 | puniform (star) | 157.696 |
RMSE (Root Mean Square Error) is an overall summary measure of estimation performance that combines bias and empirical SE. RMSE is the square root of the average squared difference between the meta-analytic estimate and the true effect across simulation runs. A lower RMSE indicates a better method.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | MAIVE (WAIVE) | 0.093 | 1 | puniform (default) | -0.069 |
| 2 | SM (4PSM) | 0.160 | 2 | MAIVE (WAIVE) | 0.093 |
| 3 | EK (default) | 0.171 | 3 | SM (4PSM) | 0.166 |
| 4 | PET (default) | 0.171 | 4 | EK (default) | 0.171 |
| 5 | RoBMA (PSMA) | 0.184 | 5 | PET (default) | 0.171 |
| 6 | MAIVE (default) | 0.191 | 6 | MAIVE (default) | 0.191 |
| 7 | SM (3PSM) | 0.214 | 7 | RoBMA (PSMA) | 0.204 |
| 8 | PETPEESE (default) | 0.220 | 8 | PETPEESE (default) | 0.220 |
| 9 | AK (AK2) | 0.231 | 9 | SM (3PSM) | 0.222 |
| 10 | puniform (default) | -0.240 | 10 | WILS (default) | 0.240 |
| 11 | WILS (default) | 0.240 | 11 | AK (AK1) | 0.253 |
| 12 | AK (AK1) | 0.248 | 12 | AK (AK2) | 0.259 |
| 13 | PEESE (default) | 0.284 | 13 | PEESE (default) | 0.284 |
| 14 | trimfill (default) | 0.329 | 14 | trimfill (default) | 0.329 |
| 15 | WAAPWLS (default) | 0.335 | 15 | WAAPWLS (default) | 0.335 |
| 16 | FMA (default) | 0.356 | 16 | FMA (default) | 0.356 |
| 17 | WLS (default) | 0.356 | 17 | WLS (default) | 0.356 |
| 18 | RMA (default) | 0.375 | 18 | RMA (default) | 0.375 |
| 19 | mean (default) | 0.464 | 19 | mean (default) | 0.464 |
| 20 | pcurve (default) | 0.933 | 20 | pcurve (default) | 0.698 |
| 21 | puniform (star) | -3.661 | 21 | puniform (star) | -3.661 |
Bias is the average difference between the meta-analytic estimate and the true effect across simulation runs. Ideally, this value should be close to 0.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | FMA (default) | 0.058 | 1 | FMA (default) | 0.058 |
| 2 | WLS (default) | 0.058 | 2 | WLS (default) | 0.058 |
| 3 | trimfill (default) | 0.060 | 3 | trimfill (default) | 0.060 |
| 4 | RMA (default) | 0.061 | 4 | RMA (default) | 0.061 |
| 5 | RoBMA (PSMA) | 0.064 | 5 | WAAPWLS (default) | 0.067 |
| 6 | WAAPWLS (default) | 0.067 | 6 | WILS (default) | 0.075 |
| 7 | WILS (default) | 0.075 | 7 | PEESE (default) | 0.088 |
| 8 | AK (AK2) | 0.075 | 8 | RoBMA (PSMA) | 0.091 |
| 9 | PEESE (default) | 0.088 | 9 | SM (3PSM) | 0.095 |
| 10 | SM (3PSM) | 0.100 | 10 | mean (default) | 0.113 |
| 11 | mean (default) | 0.113 | 11 | PETPEESE (default) | 0.134 |
| 12 | PETPEESE (default) | 0.134 | 12 | EK (default) | 0.141 |
| 13 | EK (default) | 0.141 | 13 | PET (default) | 0.142 |
| 14 | PET (default) | 0.142 | 14 | SM (4PSM) | 0.170 |
| 15 | SM (4PSM) | 0.179 | 15 | MAIVE (default) | 0.209 |
| 16 | MAIVE (default) | 0.209 | 16 | MAIVE (WAIVE) | 0.375 |
| 17 | MAIVE (WAIVE) | 0.375 | 17 | pcurve (default) | 0.843 |
| 18 | pcurve (default) | 0.812 | 18 | AK (AK2) | 0.861 |
| 19 | AK (AK1) | 1.373 | 19 | puniform (default) | 1.175 |
| 20 | puniform (default) | 1.516 | 20 | AK (AK1) | 1.222 |
| 21 | puniform (star) | 156.858 | 21 | puniform (star) | 156.858 |
The empirical SE is the standard deviation of the meta-analytic estimate across simulation runs. A lower empirical SE indicates less variability and better method performance.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | MAIVE (WAIVE) | 3.195 | 1 | MAIVE (WAIVE) | 3.195 |
| 2 | EK (default) | 3.581 | 2 | EK (default) | 3.581 |
| 3 | PET (default) | 3.689 | 3 | PET (default) | 3.689 |
| 4 | RoBMA (PSMA) | 3.887 | 4 | RoBMA (PSMA) | 4.717 |
| 5 | SM (4PSM) | 4.723 | 5 | SM (4PSM) | 4.768 |
| 6 | MAIVE (default) | 4.790 | 6 | MAIVE (default) | 4.790 |
| 7 | SM (3PSM) | 5.619 | 7 | SM (3PSM) | 5.735 |
| 8 | puniform (star) | 5.831 | 8 | puniform (star) | 5.831 |
| 9 | AK (AK2) | 5.959 | 9 | puniform (default) | 6.525 |
| 10 | PETPEESE (default) | 6.582 | 10 | PETPEESE (default) | 6.582 |
| 11 | WILS (default) | 7.531 | 11 | WILS (default) | 7.531 |
| 12 | PEESE (default) | 7.667 | 12 | PEESE (default) | 7.667 |
| 13 | puniform (default) | 7.877 | 13 | trimfill (default) | 9.544 |
| 14 | trimfill (default) | 9.543 | 14 | WAAPWLS (default) | 9.694 |
| 15 | WAAPWLS (default) | 9.694 | 15 | FMA (default) | 10.660 |
| 16 | FMA (default) | 10.660 | 16 | WLS (default) | 10.776 |
| 17 | WLS (default) | 10.776 | 17 | RMA (default) | 10.804 |
| 18 | RMA (default) | 10.804 | 18 | AK (AK2) | 12.194 |
| 19 | mean (default) | 13.014 | 19 | mean (default) | 13.014 |
| 20 | AK (AK1) | 44.040 | 20 | AK (AK1) | 32.961 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
The interval score measures the accuracy of a confidence interval by combining its width and coverage. It penalizes intervals that are too wide or that fail to include the true value. A lower interval score indicates a better method.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | MAIVE (WAIVE) | 0.804 | 1 | MAIVE (WAIVE) | 0.804 |
| 2 | RoBMA (PSMA) | 0.661 | 2 | MAIVE (default) | 0.643 |
| 3 | MAIVE (default) | 0.643 | 3 | RoBMA (PSMA) | 0.625 |
| 4 | puniform (default) | 0.592 | 4 | puniform (default) | 0.588 |
| 5 | EK (default) | 0.574 | 5 | EK (default) | 0.574 |
| 6 | PET (default) | 0.548 | 6 | PET (default) | 0.548 |
| 7 | PETPEESE (default) | 0.496 | 7 | PETPEESE (default) | 0.496 |
| 8 | SM (4PSM) | 0.454 | 8 | SM (4PSM) | 0.443 |
| 9 | puniform (star) | 0.440 | 9 | puniform (star) | 0.440 |
| 10 | SM (3PSM) | 0.423 | 10 | SM (3PSM) | 0.407 |
| 11 | AK (AK2) | 0.394 | 11 | WILS (default) | 0.343 |
| 12 | WILS (default) | 0.343 | 12 | AK (AK1) | 0.319 |
| 13 | AK (AK1) | 0.321 | 13 | mean (default) | 0.314 |
| 14 | mean (default) | 0.314 | 14 | AK (AK2) | 0.297 |
| 15 | PEESE (default) | 0.277 | 15 | PEESE (default) | 0.277 |
| 16 | trimfill (default) | 0.231 | 16 | trimfill (default) | 0.231 |
| 17 | RMA (default) | 0.226 | 17 | RMA (default) | 0.226 |
| 18 | FMA (default) | 0.213 | 18 | FMA (default) | 0.213 |
| 19 | WAAPWLS (default) | 0.205 | 19 | WAAPWLS (default) | 0.205 |
| 20 | WLS (default) | 0.200 | 20 | WLS (default) | 0.200 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
95% CI coverage is the proportion of simulation runs in which the 95% confidence interval contained the true effect. Ideally, this value should be close to the nominal level of 95%.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | WILS (default) | 0.221 | 1 | WILS (default) | 0.221 |
| 2 | WLS (default) | 0.235 | 2 | WLS (default) | 0.235 |
| 3 | WAAPWLS (default) | 0.249 | 3 | WAAPWLS (default) | 0.249 |
| 4 | FMA (default) | 0.250 | 4 | FMA (default) | 0.250 |
| 5 | RoBMA (PSMA) | 0.271 | 5 | RoBMA (PSMA) | 0.271 |
| 6 | trimfill (default) | 0.274 | 6 | trimfill (default) | 0.274 |
| 7 | RMA (default) | 0.298 | 7 | RMA (default) | 0.298 |
| 8 | PEESE (default) | 0.299 | 8 | PEESE (default) | 0.299 |
| 9 | AK (AK2) | 0.322 | 9 | SM (3PSM) | 0.332 |
| 10 | SM (3PSM) | 0.344 | 10 | puniform (star) | 0.407 |
| 11 | puniform (star) | 0.407 | 11 | PETPEESE (default) | 0.457 |
| 12 | PETPEESE (default) | 0.457 | 12 | SM (4PSM) | 0.503 |
| 13 | PET (default) | 0.536 | 13 | PET (default) | 0.536 |
| 14 | SM (4PSM) | 0.569 | 14 | EK (default) | 0.658 |
| 15 | EK (default) | 0.658 | 15 | MAIVE (default) | 1.017 |
| 16 | MAIVE (default) | 1.017 | 16 | MAIVE (WAIVE) | 1.251 |
| 17 | MAIVE (WAIVE) | 1.251 | 17 | mean (default) | 1.505 |
| 18 | mean (default) | 1.505 | 18 | puniform (default) | 2.751 |
| 19 | puniform (default) | 4.072 | 19 | AK (AK2) | 5.859 |
| 20 | AK (AK1) | 38.095 | 20 | AK (AK1) | 26.987 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
95% CI width is the average length of the 95% confidence interval for the true effect. A lower average 95% CI length indicates a better method.
| Rank | Method | Log Value | Rank | Method | Log Value |
|---|---|---|---|---|---|
| 1 | RoBMA (PSMA) | 5.471 | 1 | puniform (default) | 4.298 |
| 2 | puniform (default) | 4.600 | 2 | RoBMA (PSMA) | 2.869 |
| 3 | puniform (star) | 2.747 | 3 | puniform (star) | 2.747 |
| 4 | AK (AK2) | 2.708 | 4 | SM (3PSM) | 2.476 |
| 5 | SM (3PSM) | 2.473 | 5 | PETPEESE (default) | 2.425 |
| 6 | PETPEESE (default) | 2.425 | 6 | WILS (default) | 2.268 |
| 7 | WILS (default) | 2.268 | 7 | MAIVE (default) | 2.125 |
| 8 | MAIVE (default) | 2.125 | 8 | AK (AK1) | 1.940 |
| 9 | AK (AK1) | 2.070 | 9 | EK (default) | 1.922 |
| 10 | EK (default) | 1.922 | 10 | PET (default) | 1.913 |
| 11 | PET (default) | 1.913 | 11 | AK (AK2) | 1.782 |
| 12 | FMA (default) | 1.678 | 12 | FMA (default) | 1.678 |
| 13 | PEESE (default) | 1.605 | 13 | PEESE (default) | 1.605 |
| 14 | mean (default) | 1.593 | 14 | mean (default) | 1.593 |
| 15 | RMA (default) | 1.539 | 15 | RMA (default) | 1.539 |
| 16 | WLS (default) | 1.530 | 16 | WLS (default) | 1.530 |
| 17 | WAAPWLS (default) | 1.469 | 17 | SM (4PSM) | 1.478 |
| 18 | trimfill (default) | 1.432 | 18 | WAAPWLS (default) | 1.469 |
| 19 | SM (4PSM) | 1.425 | 19 | trimfill (default) | 1.432 |
| 20 | MAIVE (WAIVE) | 1.239 | 20 | MAIVE (WAIVE) | 1.239 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
The positive likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a positive likelihood ratio greater than 1 (or a log positive likelihood ratio greater than 0). A higher (log) positive likelihood ratio indicates a better method.
| Rank | Method | Log Value | Rank | Method | Log Value |
|---|---|---|---|---|---|
| 1 | WILS (default) | -5.267 | 1 | AK (AK2) | -5.801 |
| 2 | puniform (star) | -4.910 | 2 | WILS (default) | -5.267 |
| 3 | SM (3PSM) | -4.904 | 3 | SM (3PSM) | -4.940 |
| 4 | PEESE (default) | -4.288 | 4 | puniform (star) | -4.910 |
| 5 | FMA (default) | -3.859 | 5 | PEESE (default) | -4.288 |
| 6 | WLS (default) | -3.837 | 6 | FMA (default) | -3.859 |
| 7 | AK (AK2) | -3.785 | 7 | WLS (default) | -3.837 |
| 8 | RMA (default) | -3.730 | 8 | RMA (default) | -3.730 |
| 9 | trimfill (default) | -3.682 | 9 | trimfill (default) | -3.682 |
| 10 | PETPEESE (default) | -3.556 | 10 | PETPEESE (default) | -3.556 |
| 11 | AK (AK1) | -3.477 | 11 | AK (AK1) | -3.488 |
| 12 | EK (default) | -3.238 | 12 | EK (default) | -3.238 |
| 13 | PET (default) | -3.236 | 13 | PET (default) | -3.236 |
| 14 | SM (4PSM) | -3.063 | 14 | SM (4PSM) | -3.100 |
| 15 | puniform (default) | -2.518 | 15 | puniform (default) | -2.517 |
| 16 | RoBMA (PSMA) | -2.388 | 16 | RoBMA (PSMA) | -2.460 |
| 17 | MAIVE (default) | -2.051 | 17 | MAIVE (default) | -2.051 |
| 18 | WAAPWLS (default) | -1.596 | 18 | WAAPWLS (default) | -1.596 |
| 19 | mean (default) | -1.432 | 19 | mean (default) | -1.432 |
| 20 | MAIVE (WAIVE) | -0.308 | 20 | MAIVE (WAIVE) | -0.308 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
The negative likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a non-significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a negative likelihood ratio less than 1 (or a log negative likelihood ratio less than 0). A lower (log) negative likelihood ratio indicates a better method.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | RoBMA (PSMA) | 0.003 | 1 | puniform (default) | 0.017 |
| 2 | puniform (default) | 0.009 | 2 | puniform (star) | 0.053 |
| 3 | puniform (star) | 0.053 | 3 | PETPEESE (default) | 0.072 |
| 4 | PETPEESE (default) | 0.072 | 4 | PET (default) | 0.075 |
| 5 | PET (default) | 0.075 | 5 | EK (default) | 0.076 |
| 6 | EK (default) | 0.076 | 6 | RoBMA (PSMA) | 0.080 |
| 7 | MAIVE (default) | 0.084 | 7 | MAIVE (default) | 0.084 |
| 8 | MAIVE (WAIVE) | 0.088 | 8 | MAIVE (WAIVE) | 0.088 |
| 9 | SM (3PSM) | 0.089 | 9 | SM (3PSM) | 0.096 |
| 10 | WILS (default) | 0.099 | 10 | WILS (default) | 0.099 |
| 11 | AK (AK2) | 0.130 | 11 | SM (4PSM) | 0.238 |
| 12 | SM (4PSM) | 0.237 | 12 | AK (AK2) | 0.257 |
| 13 | PEESE (default) | 0.334 | 13 | PEESE (default) | 0.334 |
| 14 | AK (AK1) | 0.385 | 14 | AK (AK1) | 0.387 |
| 15 | mean (default) | 0.420 | 15 | mean (default) | 0.420 |
| 16 | trimfill (default) | 0.444 | 16 | trimfill (default) | 0.444 |
| 17 | WAAPWLS (default) | 0.445 | 17 | WAAPWLS (default) | 0.445 |
| 18 | WLS (default) | 0.446 | 18 | WLS (default) | 0.446 |
| 19 | RMA (default) | 0.450 | 19 | RMA (default) | 0.450 |
| 20 | FMA (default) | 0.468 | 20 | FMA (default) | 0.468 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
The type I error rate is the proportion of simulation runs in which the null hypothesis of no effect was incorrectly rejected when it was true. Ideally, this value should be close to the nominal level of 5%.
| Rank | Method | Value | Rank | Method | Value |
|---|---|---|---|---|---|
| 1 | FMA (default) | 0.958 | 1 | FMA (default) | 0.958 |
| 2 | WLS (default) | 0.950 | 2 | AK (AK2) | 0.958 |
| 3 | RMA (default) | 0.948 | 3 | WLS (default) | 0.950 |
| 4 | trimfill (default) | 0.943 | 4 | RMA (default) | 0.948 |
| 5 | WAAPWLS (default) | 0.896 | 5 | trimfill (default) | 0.943 |
| 6 | AK (AK1) | 0.893 | 6 | WAAPWLS (default) | 0.896 |
| 7 | WILS (default) | 0.888 | 7 | AK (AK1) | 0.894 |
| 8 | AK (AK2) | 0.886 | 8 | WILS (default) | 0.888 |
| 9 | PEESE (default) | 0.882 | 9 | PEESE (default) | 0.882 |
| 10 | SM (3PSM) | 0.850 | 10 | SM (3PSM) | 0.871 |
| 11 | puniform (star) | 0.842 | 11 | puniform (star) | 0.842 |
| 12 | mean (default) | 0.835 | 12 | mean (default) | 0.835 |
| 13 | SM (4PSM) | 0.742 | 13 | SM (4PSM) | 0.759 |
| 14 | PETPEESE (default) | 0.708 | 14 | PETPEESE (default) | 0.708 |
| 15 | EK (default) | 0.654 | 15 | EK (default) | 0.654 |
| 16 | PET (default) | 0.652 | 16 | PET (default) | 0.652 |
| 17 | puniform (default) | 0.591 | 17 | puniform (default) | 0.597 |
| 18 | RoBMA (PSMA) | 0.584 | 18 | RoBMA (PSMA) | 0.596 |
| 19 | MAIVE (default) | 0.572 | 19 | MAIVE (default) | 0.572 |
| 20 | MAIVE (WAIVE) | 0.256 | 20 | MAIVE (WAIVE) | 0.256 |
| 21 | pcurve (default) | NaN | 21 | pcurve (default) | NaN |
The power is the proportion of simulation runs in which the null hypothesis of no effect was correctly rejected when the alternative hypothesis was true. A higher power indicates a better method.
By-Condition Performance (Conditional on Method Convergence)
The results below are conditional on method convergence. Note that the methods might differ in convergence rate and are therefore not compared on the same data sets.
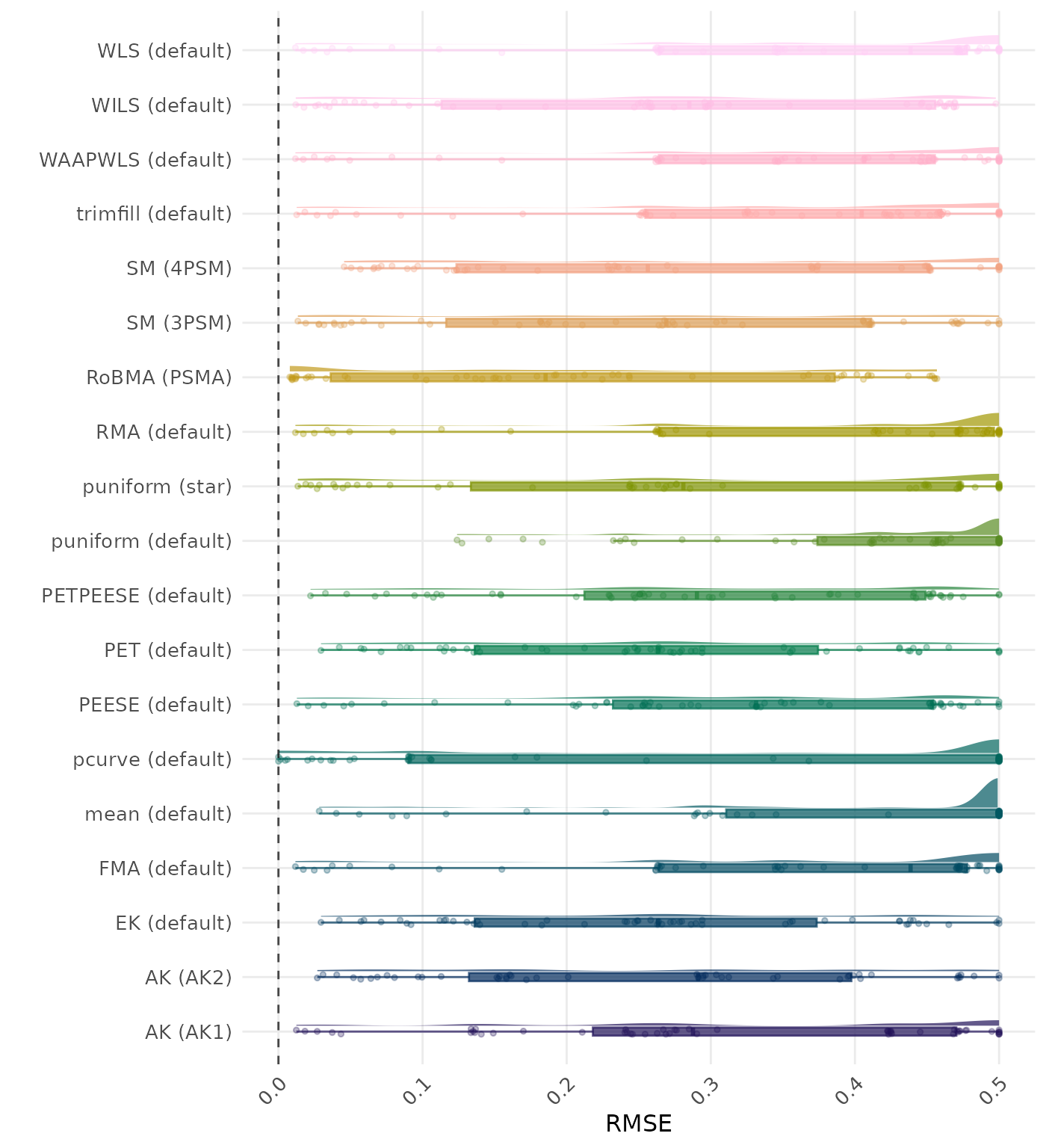
RMSE (Root Mean Square Error) is an overall summary measure of estimation performance that combines bias and empirical SE. RMSE is the square root of the average squared difference between the meta-analytic estimate and the true effect across simulation runs. A lower RMSE indicates a better method. Values larger than 0.5 are visualized as 0.5.
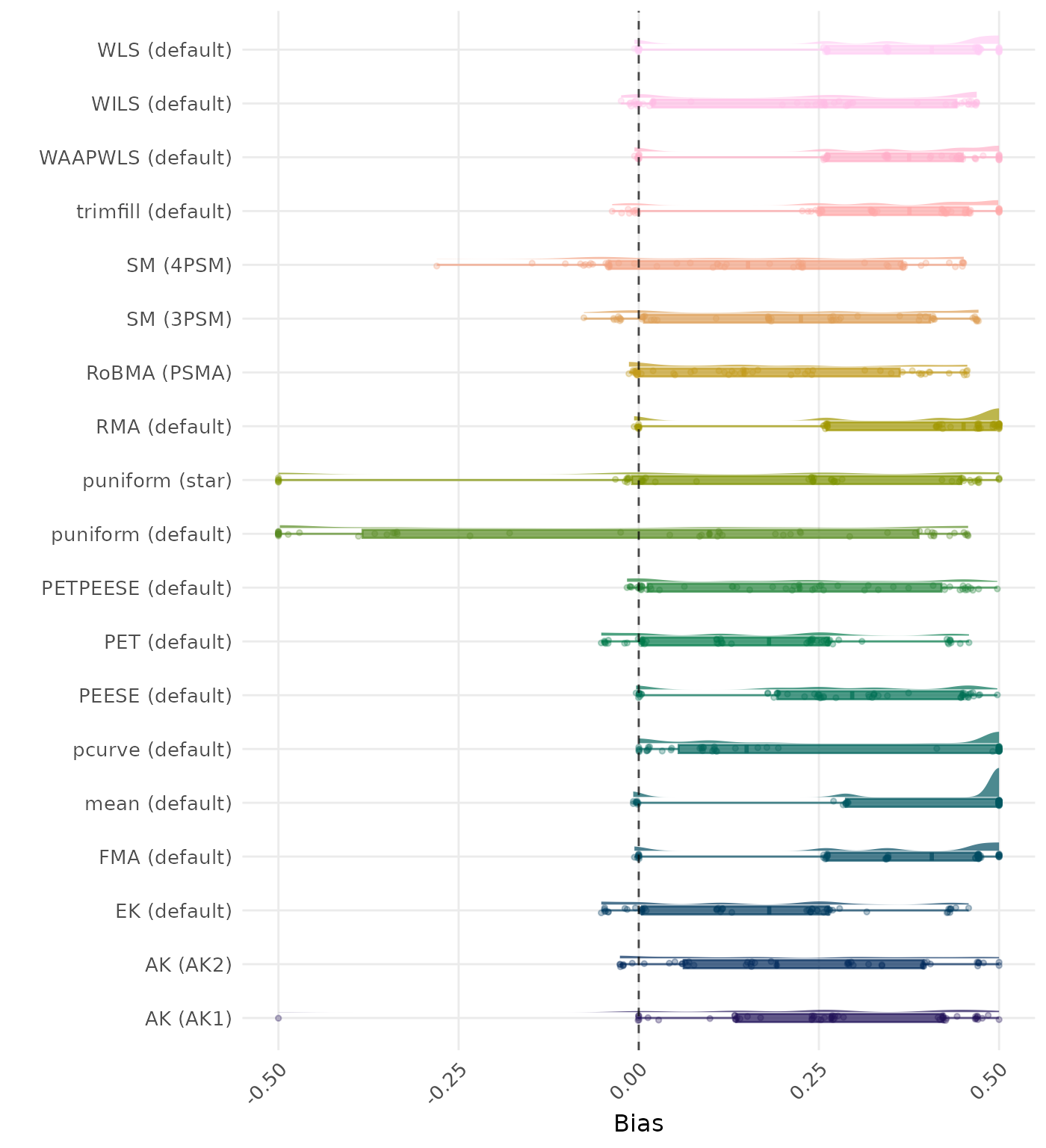
Bias is the average difference between the meta-analytic estimate and the true effect across simulation runs. Ideally, this value should be close to 0. Values lower than -0.5 or larger than 0.5 are visualized as -0.5 and 0.5 respectively.
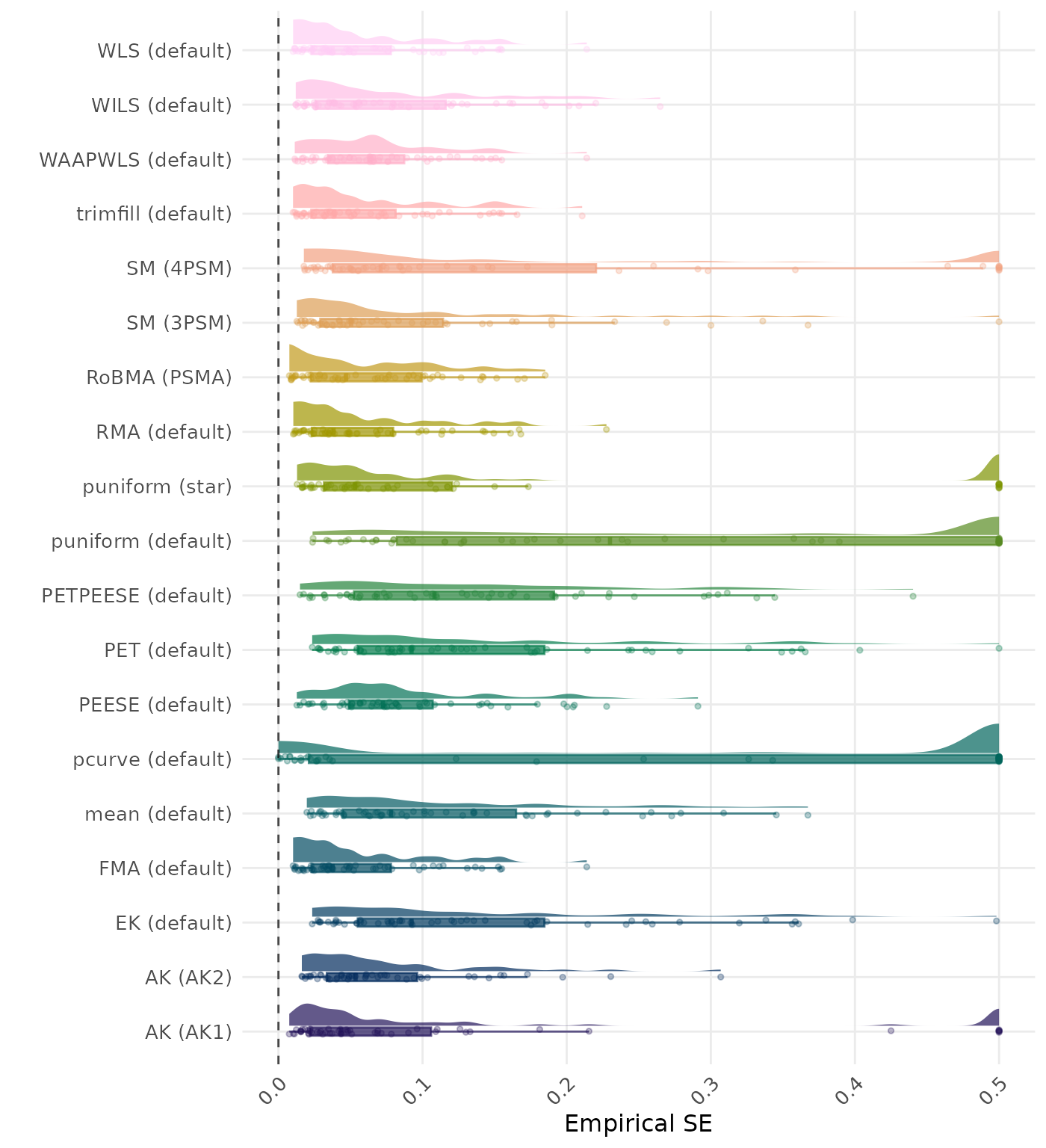
The empirical SE is the standard deviation of the meta-analytic estimate across simulation runs. A lower empirical SE indicates less variability and better method performance. Values larger than 0.5 are visualized as 0.5.
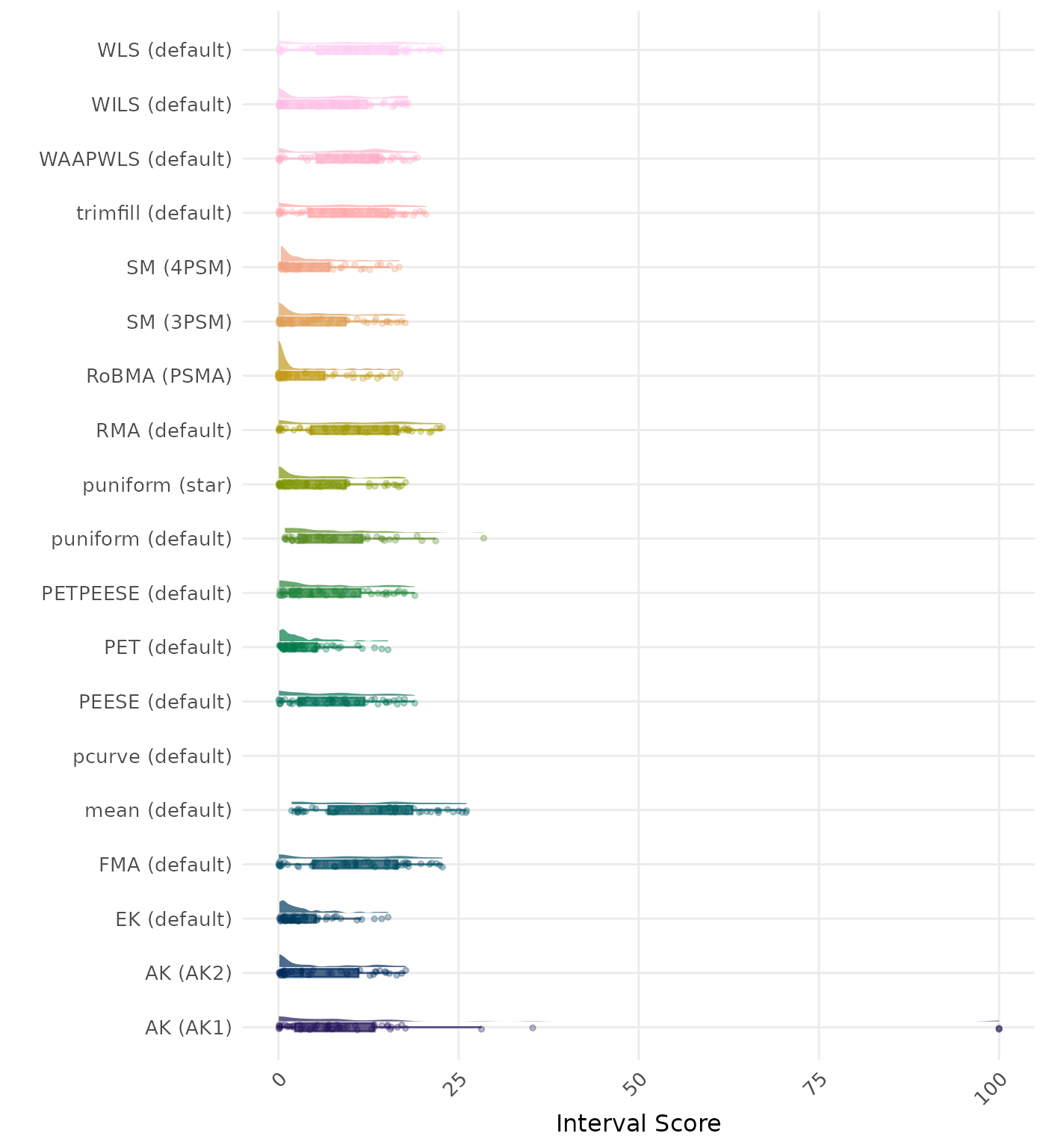
The interval score measures the accuracy of a confidence interval by combining its width and coverage. It penalizes intervals that are too wide or that fail to include the true value. A lower interval score indicates a better method. Values larger than 100 are visualized as 100.
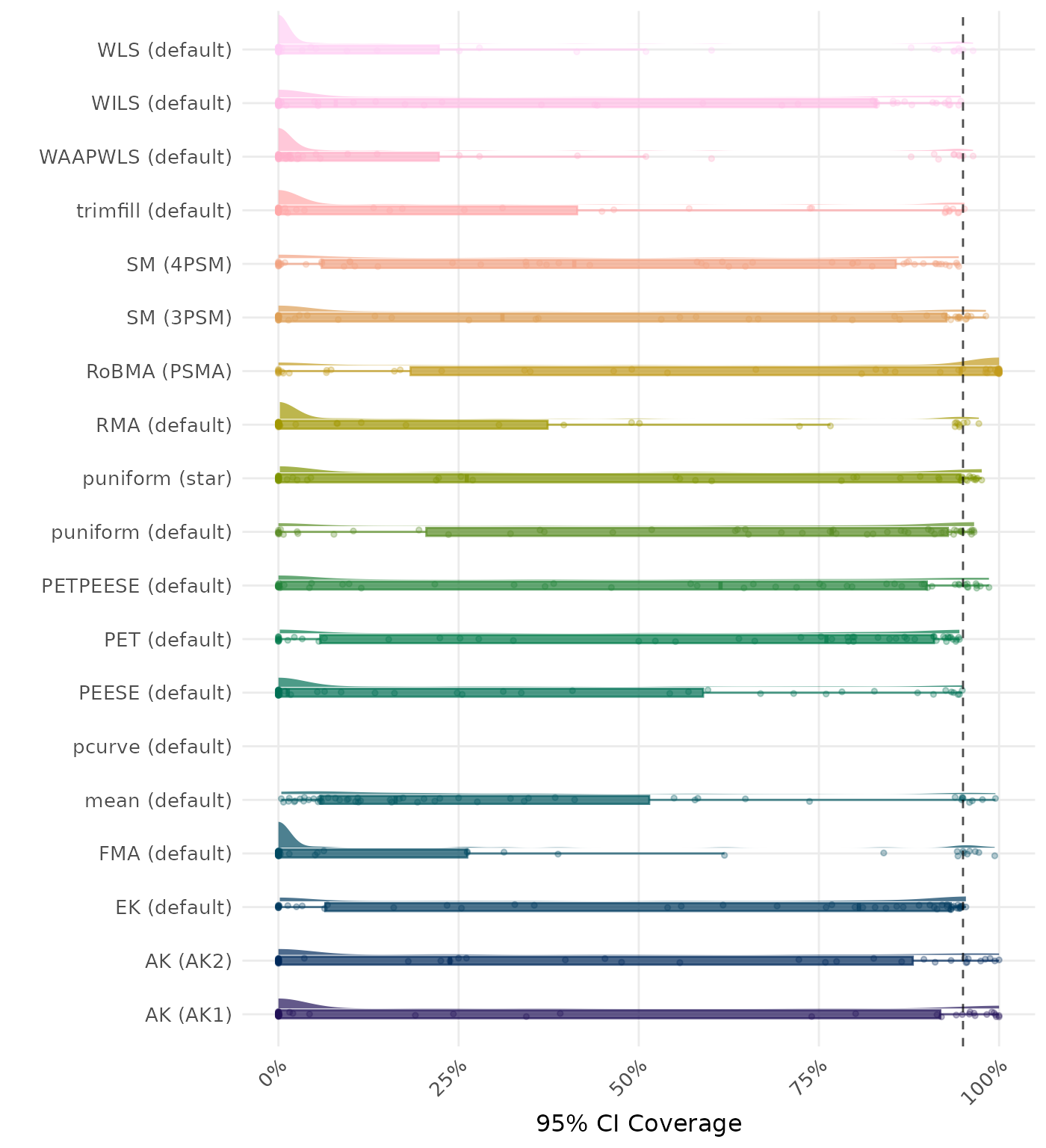
95% CI coverage is the proportion of simulation runs in which the 95% confidence interval contained the true effect. Ideally, this value should be close to the nominal level of 95%.
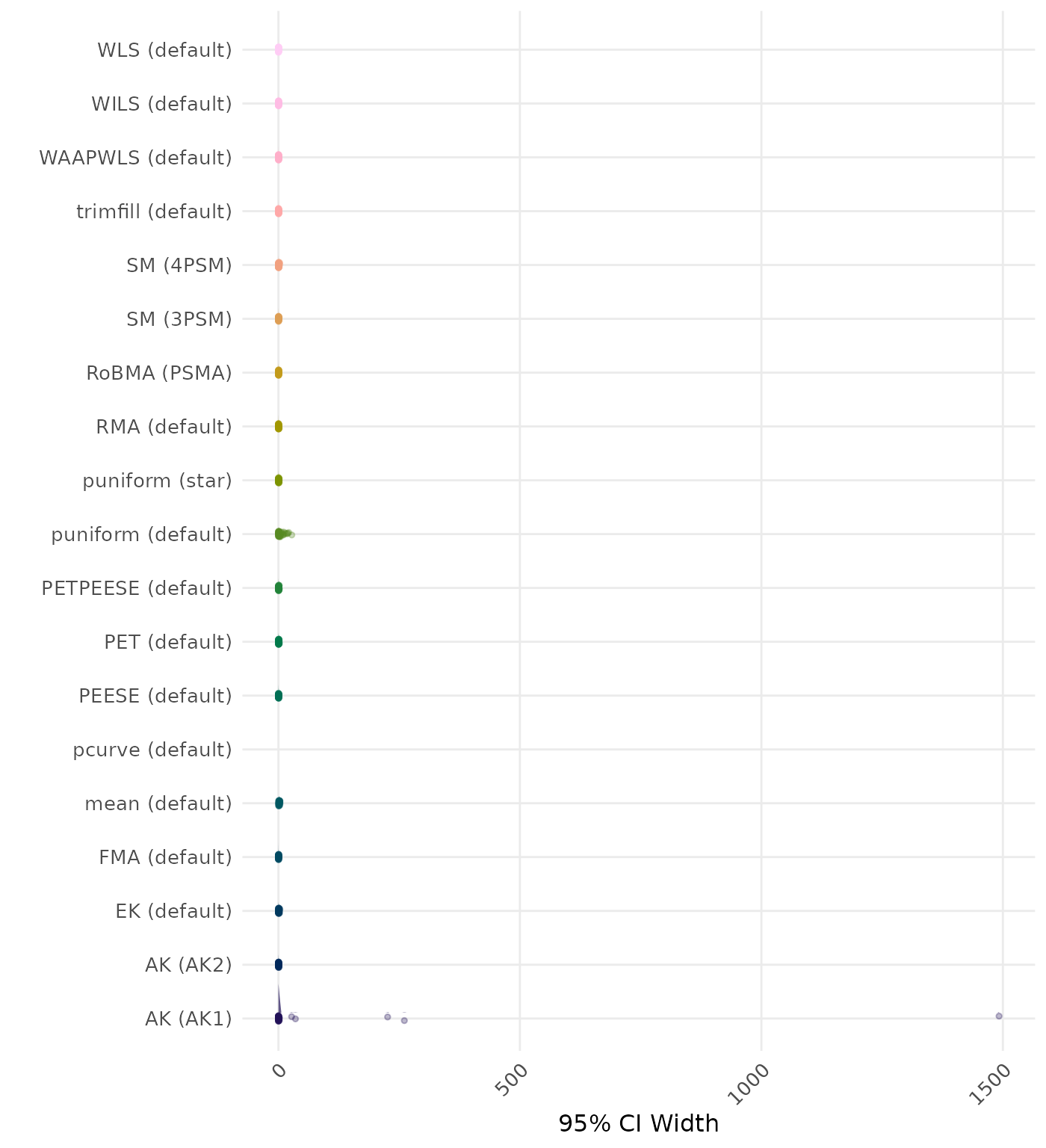
95% CI width is the average length of the 95% confidence interval for the true effect. A lower average 95% CI length indicates a better method.
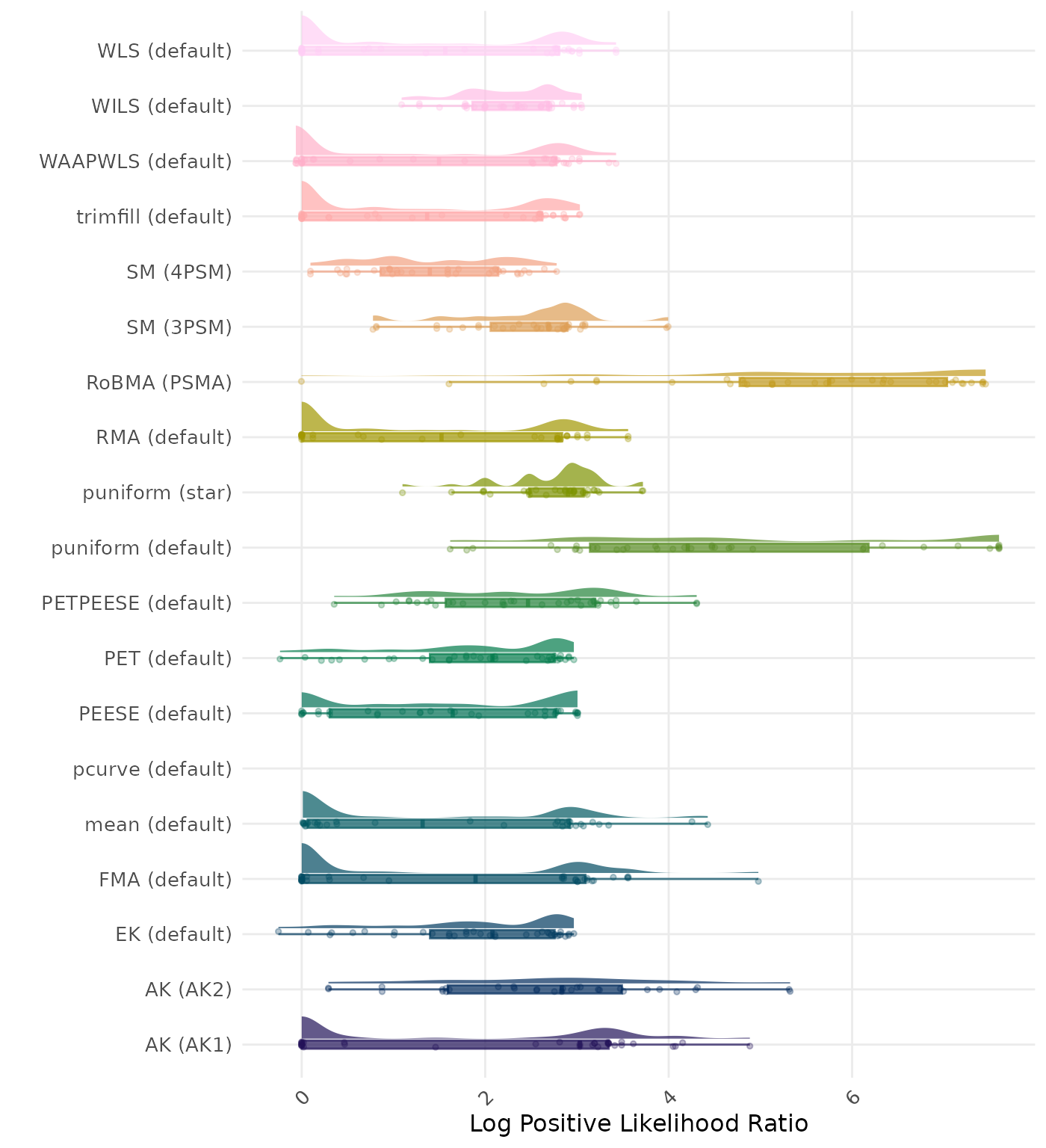
The positive likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a positive likelihood ratio greater than 1 (or a log positive likelihood ratio greater than 0). A higher (log) positive likelihood ratio indicates a better method.
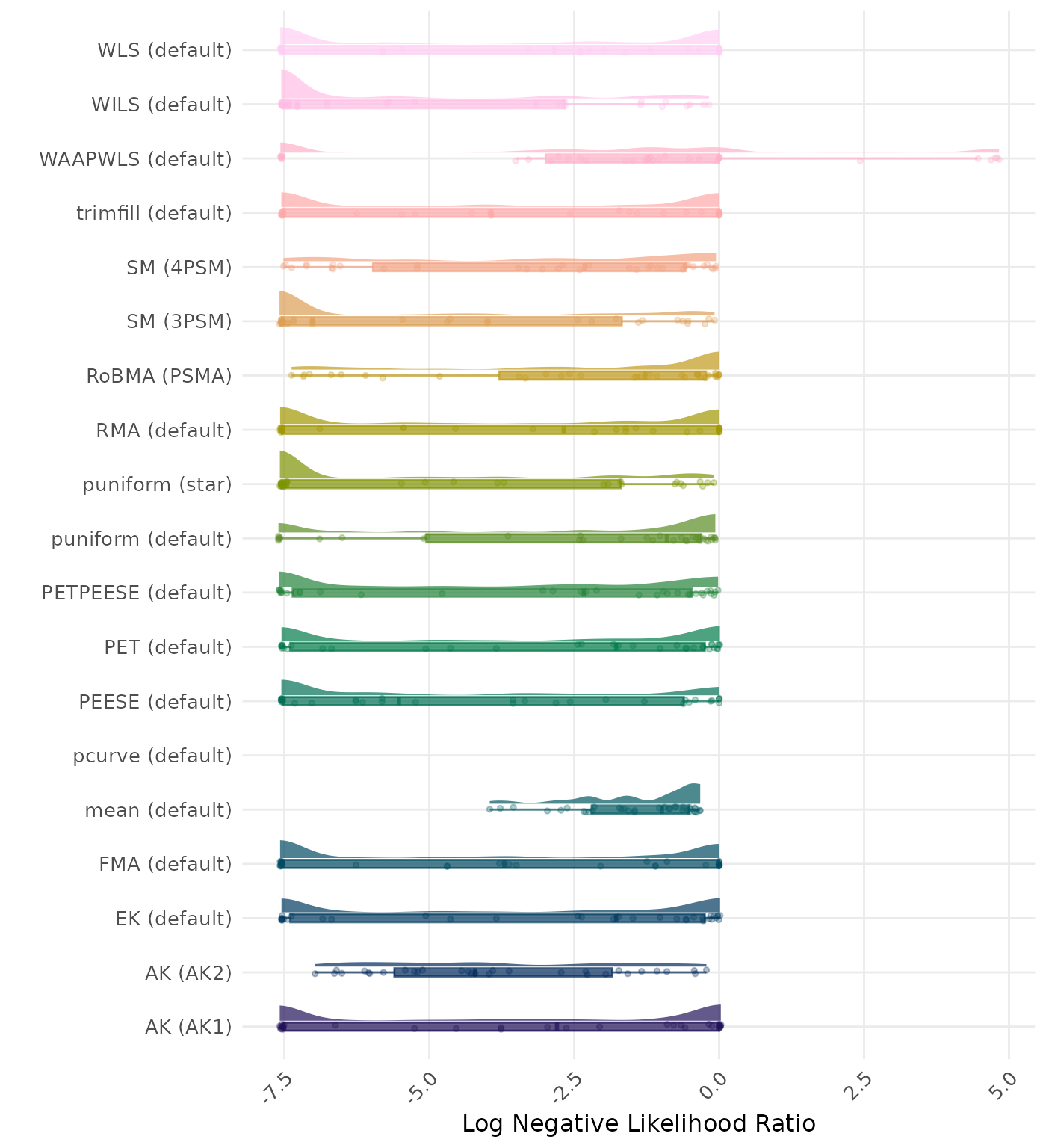
The negative likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a non-significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a negative likelihood ratio less than 1 (or a log negative likelihood ratio less than 0). A lower (log) negative likelihood ratio indicates a better method.
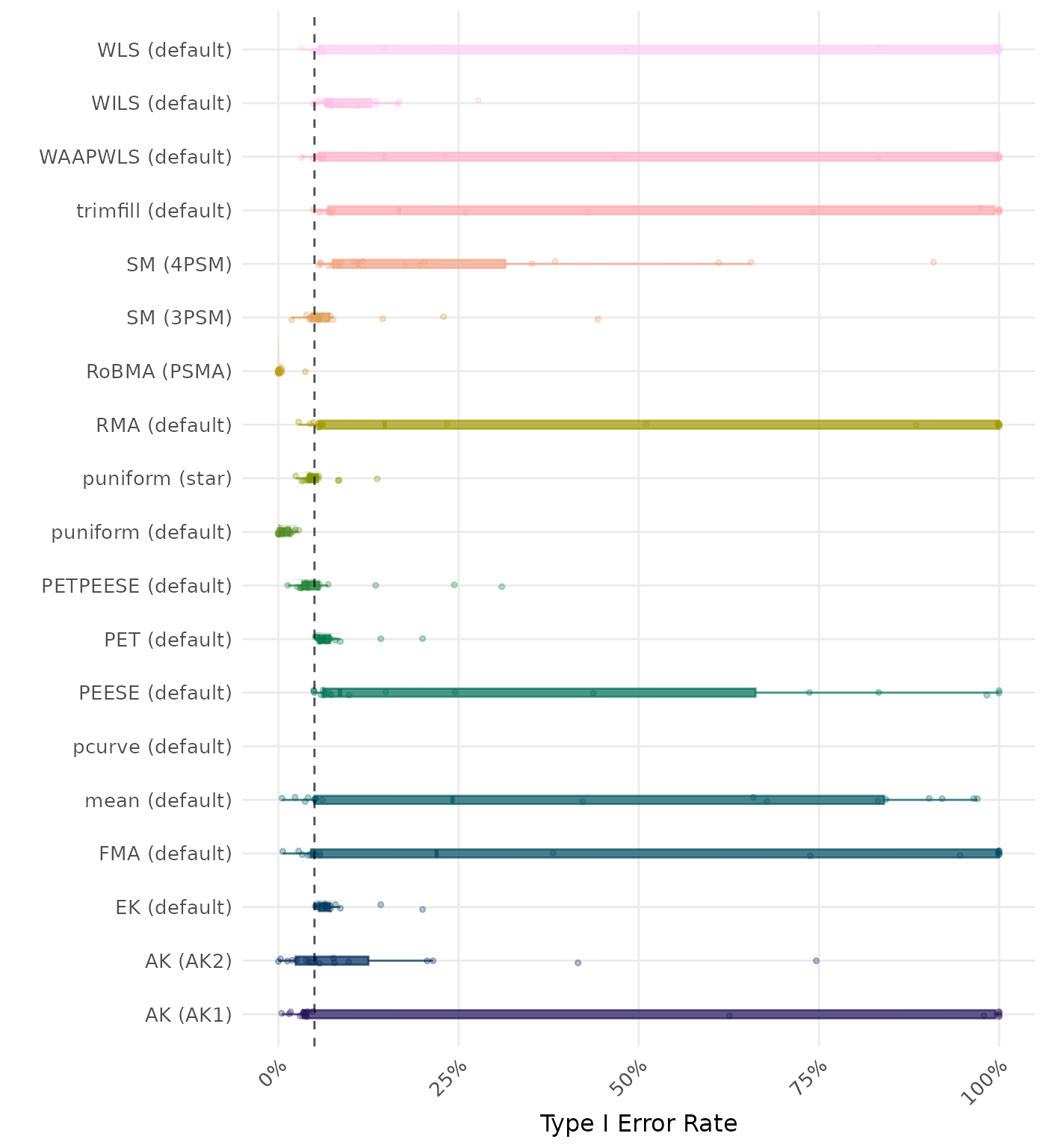
The type I error rate is the proportion of simulation runs in which the null hypothesis of no effect was incorrectly rejected when it was true. Ideally, this value should be close to the nominal level of 5%.
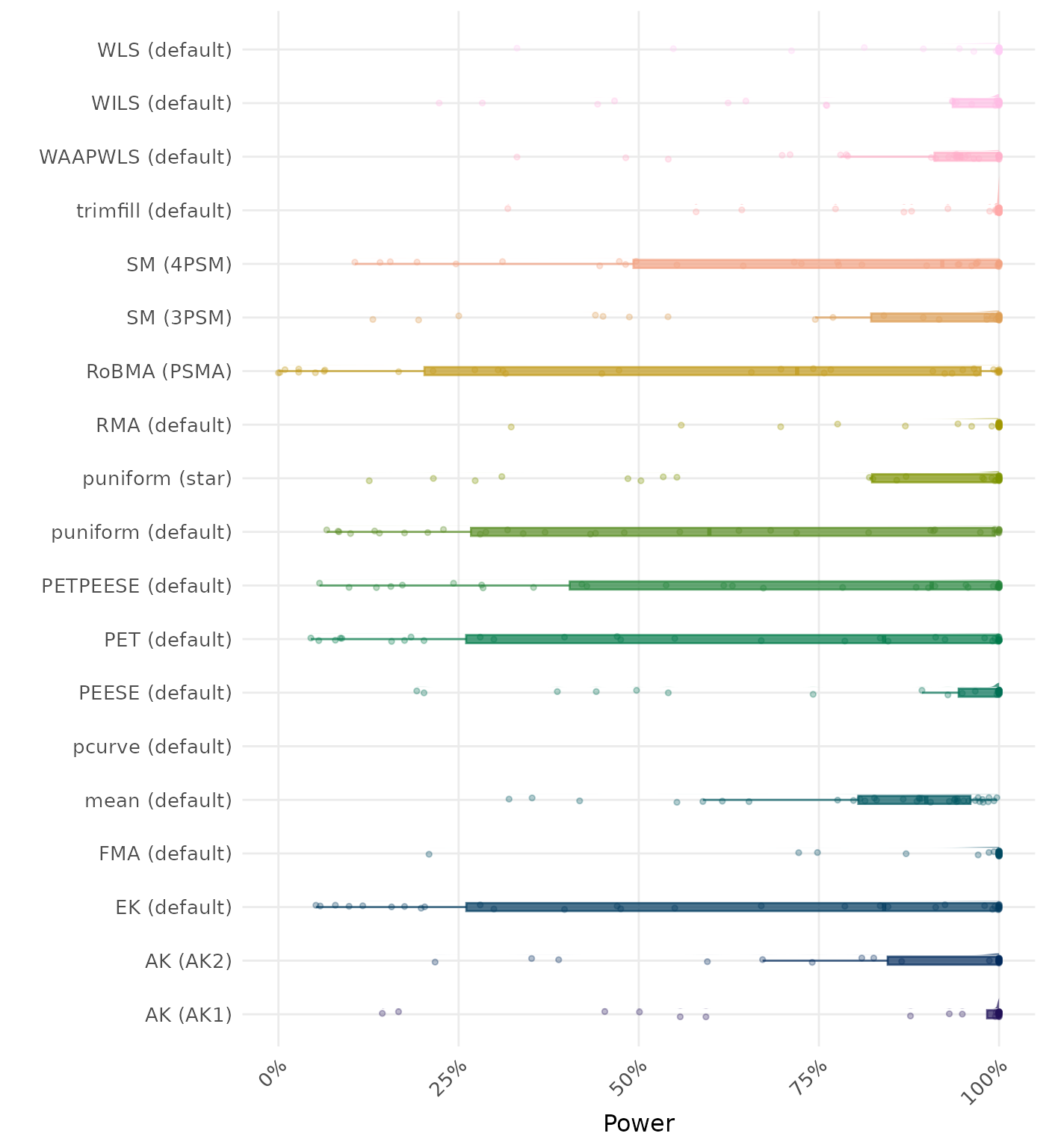
The power is the proportion of simulation runs in which the null hypothesis of no effect was correctly rejected when the alternative hypothesis was true. A higher power indicates a better method.
By-Condition Performance (Replacement in Case of Non-Convergence)
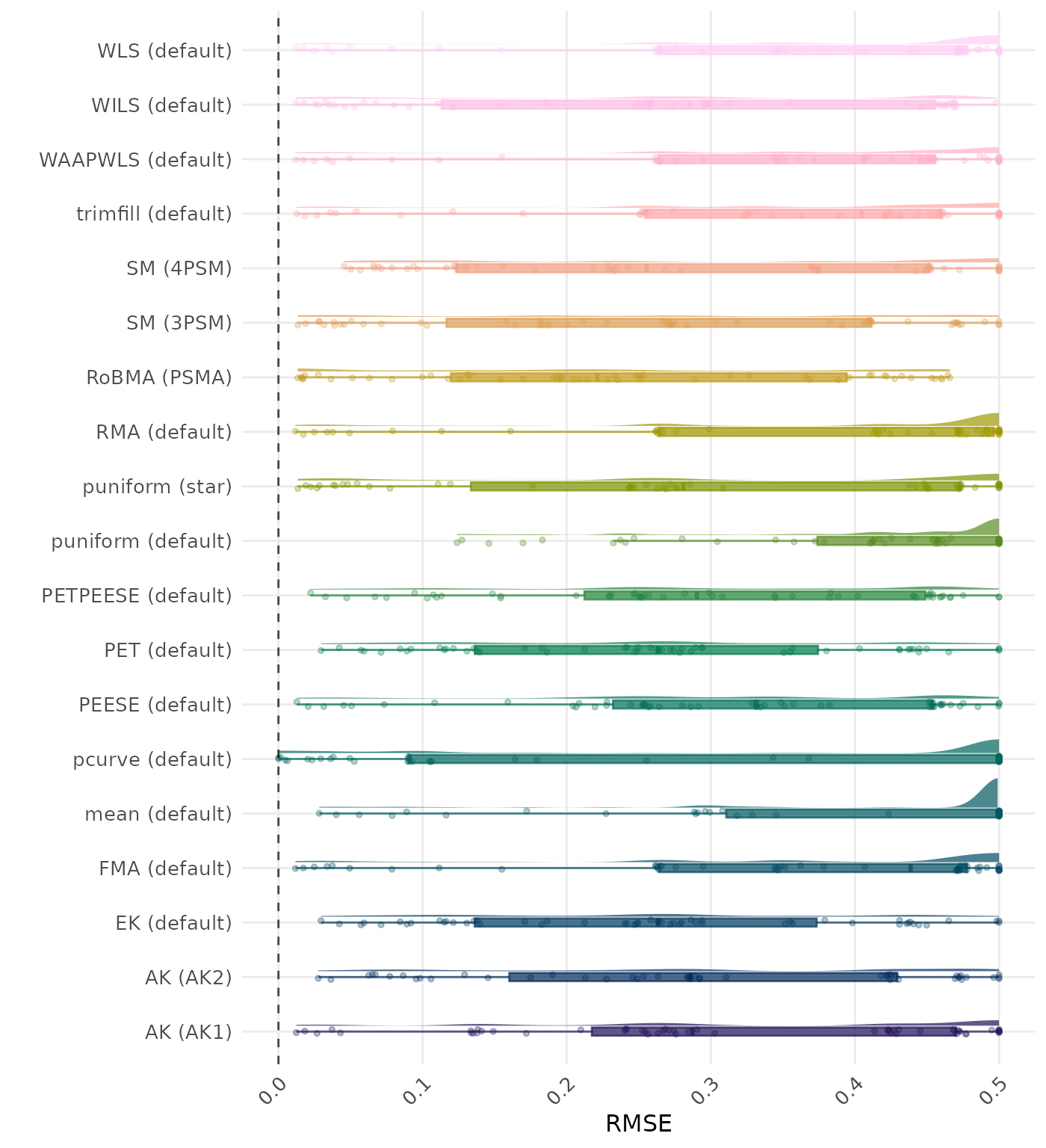
RMSE (Root Mean Square Error) is an overall summary measure of estimation performance that combines bias and empirical SE. RMSE is the square root of the average squared difference between the meta-analytic estimate and the true effect across simulation runs. A lower RMSE indicates a better method. Values larger than 0.5 are visualized as 0.5.
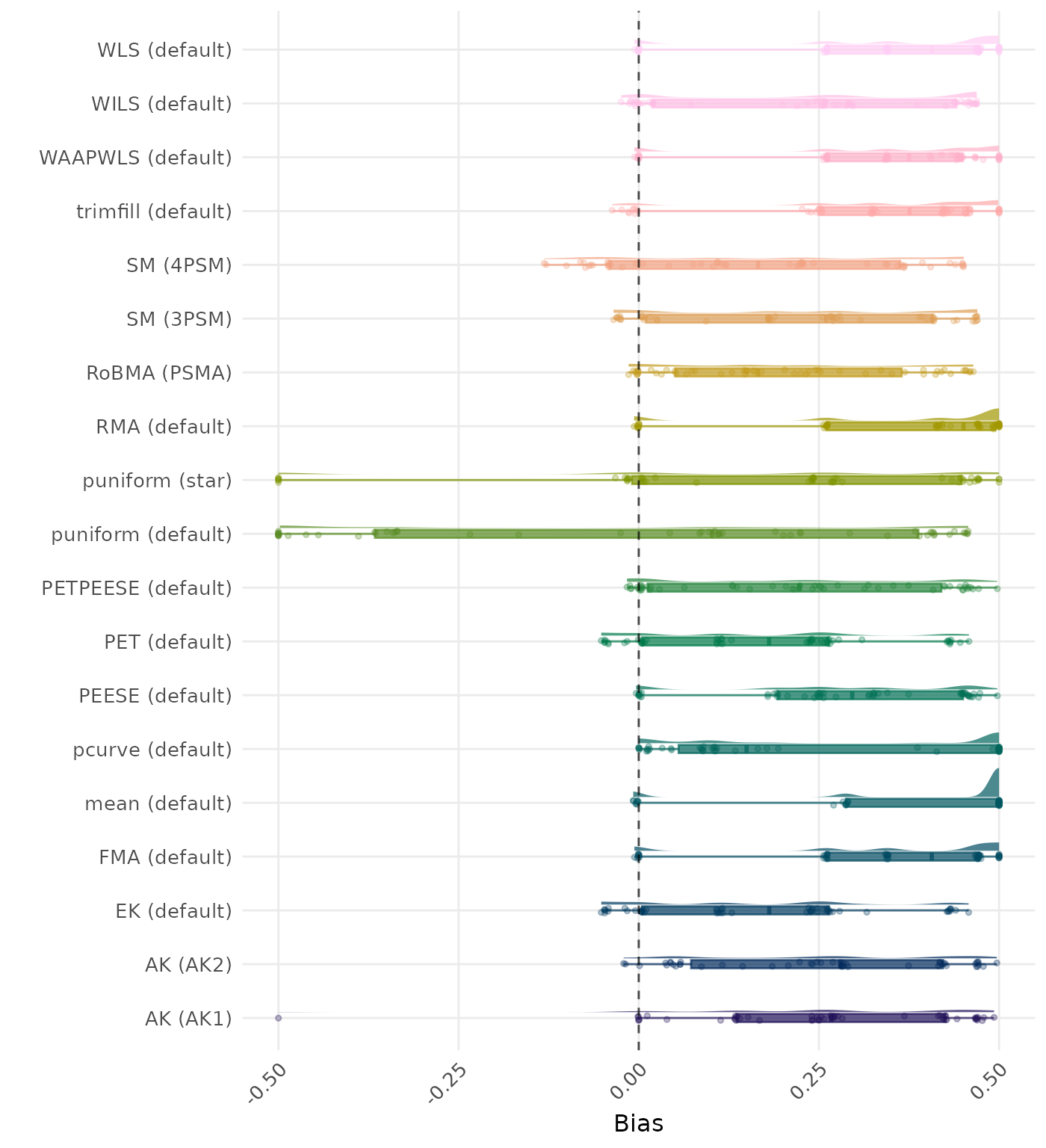
Bias is the average difference between the meta-analytic estimate and the true effect across simulation runs. Ideally, this value should be close to 0. Values lower than -0.5 or larger than 0.5 are visualized as -0.5 and 0.5 respectively.
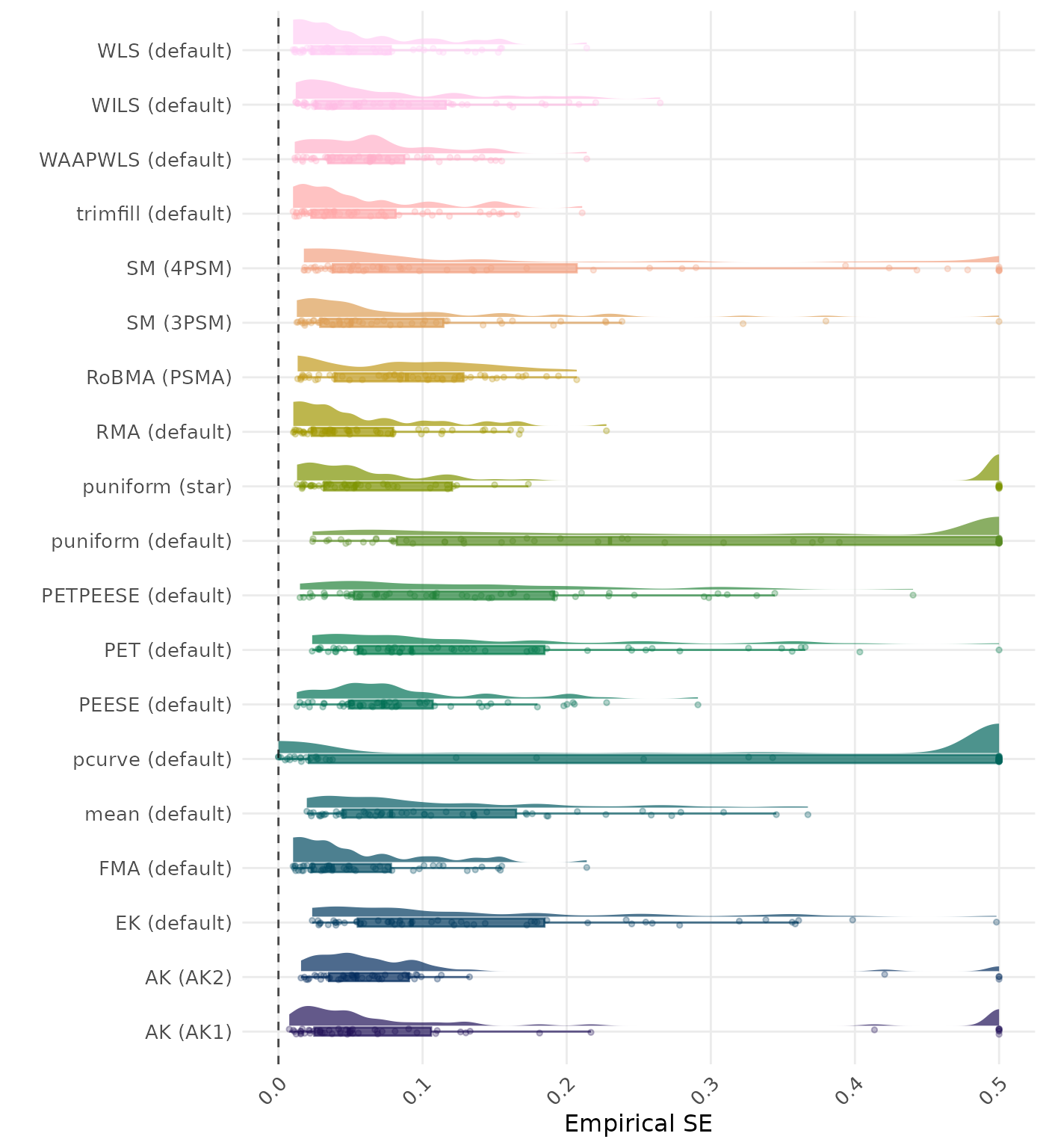
The empirical SE is the standard deviation of the meta-analytic estimate across simulation runs. A lower empirical SE indicates less variability and better method performance. Values larger than 0.5 are visualized as 0.5.
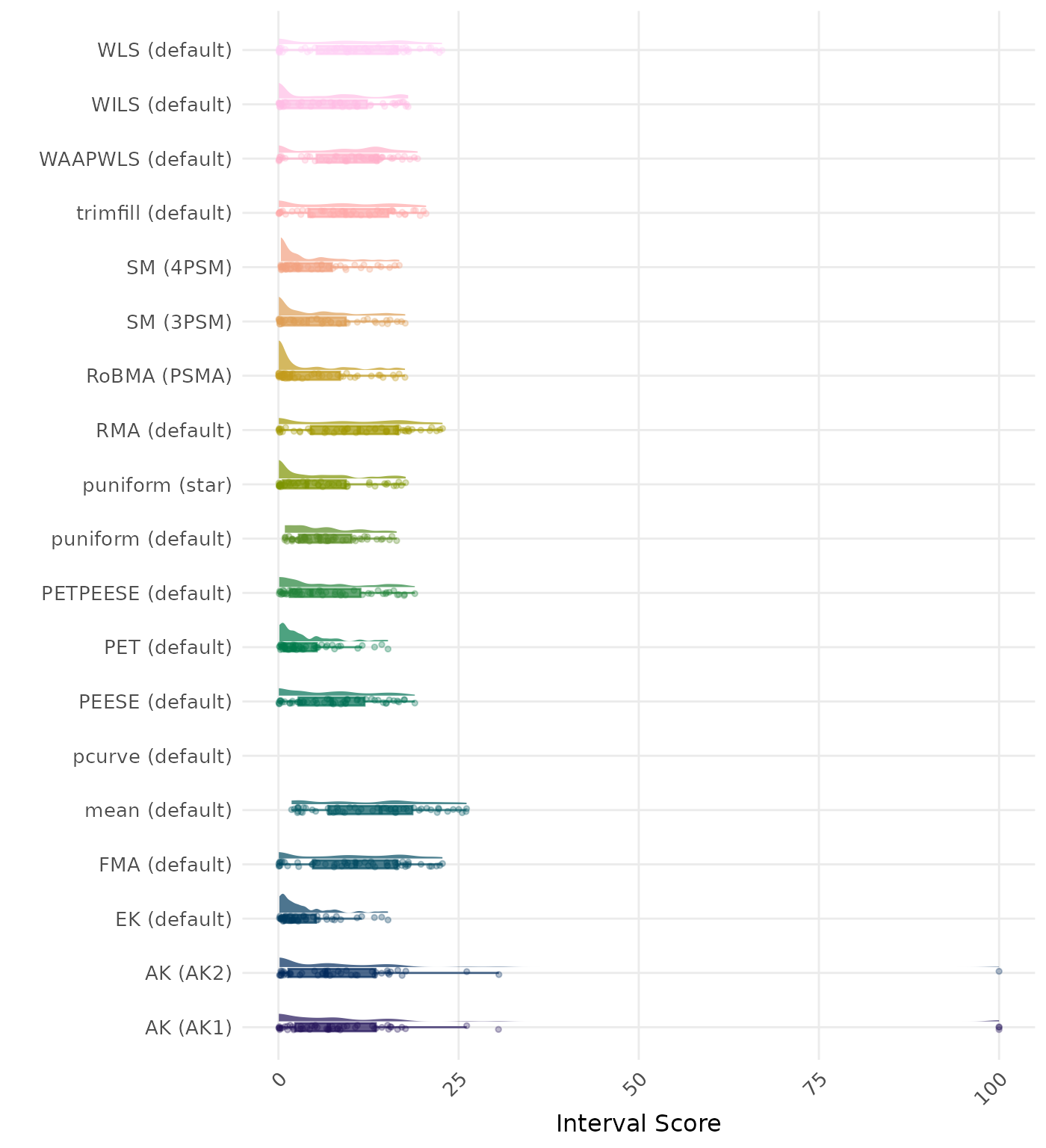
The interval score measures the accuracy of a confidence interval by combining its width and coverage. It penalizes intervals that are too wide or that fail to include the true value. A lower interval score indicates a better method. Values larger than 100 are visualized as 100.
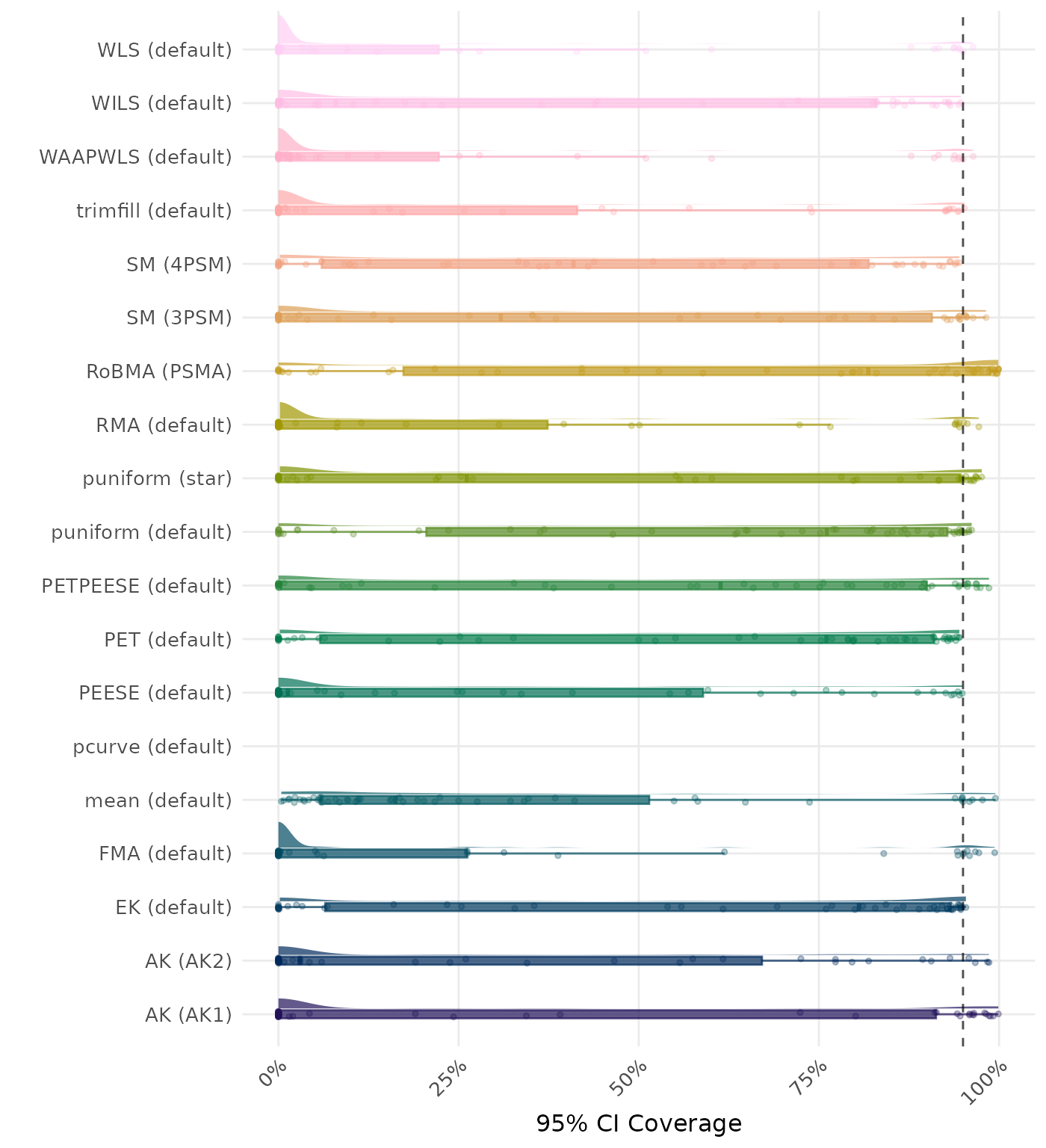
95% CI coverage is the proportion of simulation runs in which the 95% confidence interval contained the true effect. Ideally, this value should be close to the nominal level of 95%.
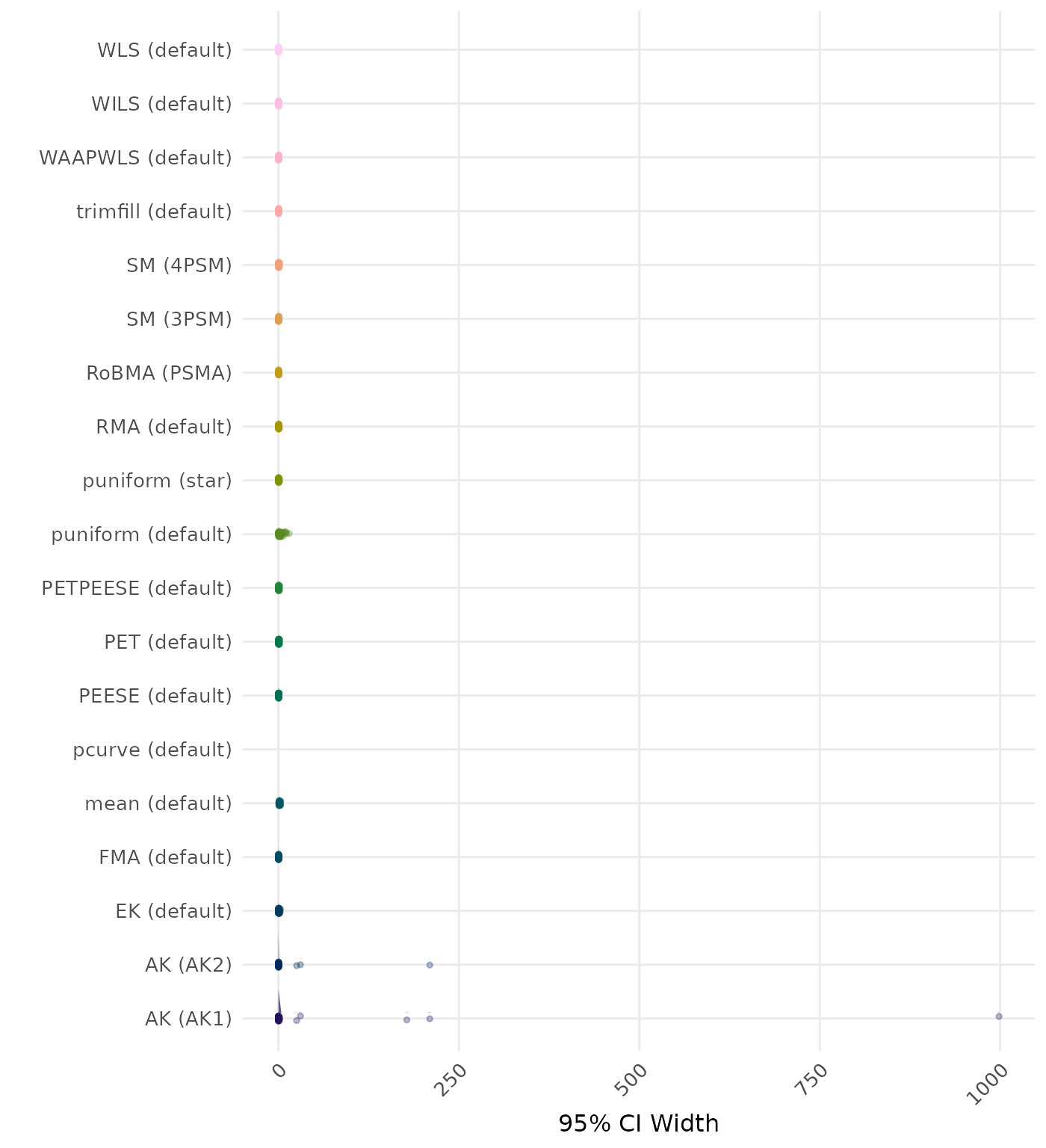
95% CI width is the average length of the 95% confidence interval for the true effect. A lower average 95% CI length indicates a better method.
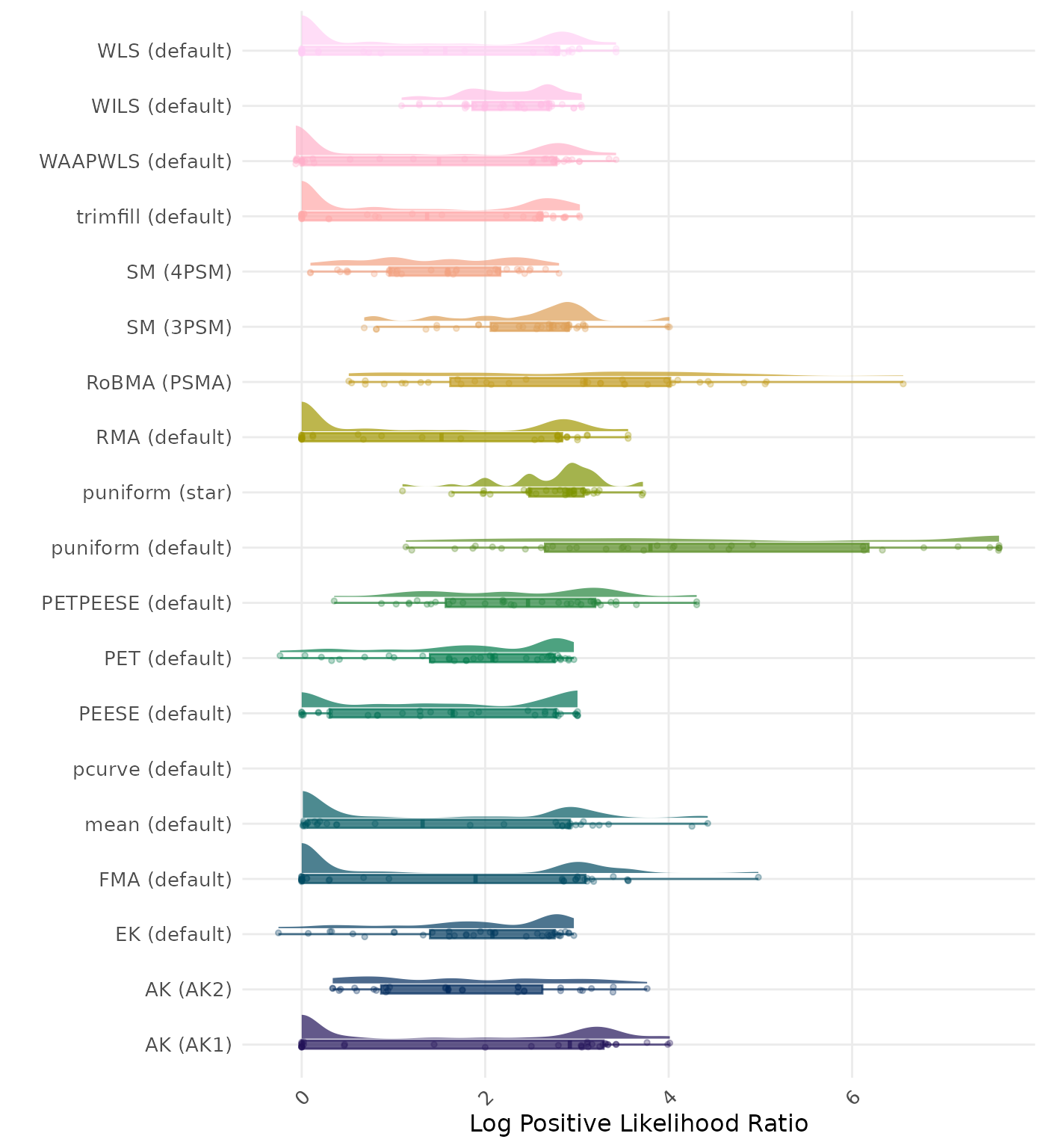
The positive likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a positive likelihood ratio greater than 1 (or a log positive likelihood ratio greater than 0). A higher (log) positive likelihood ratio indicates a better method.
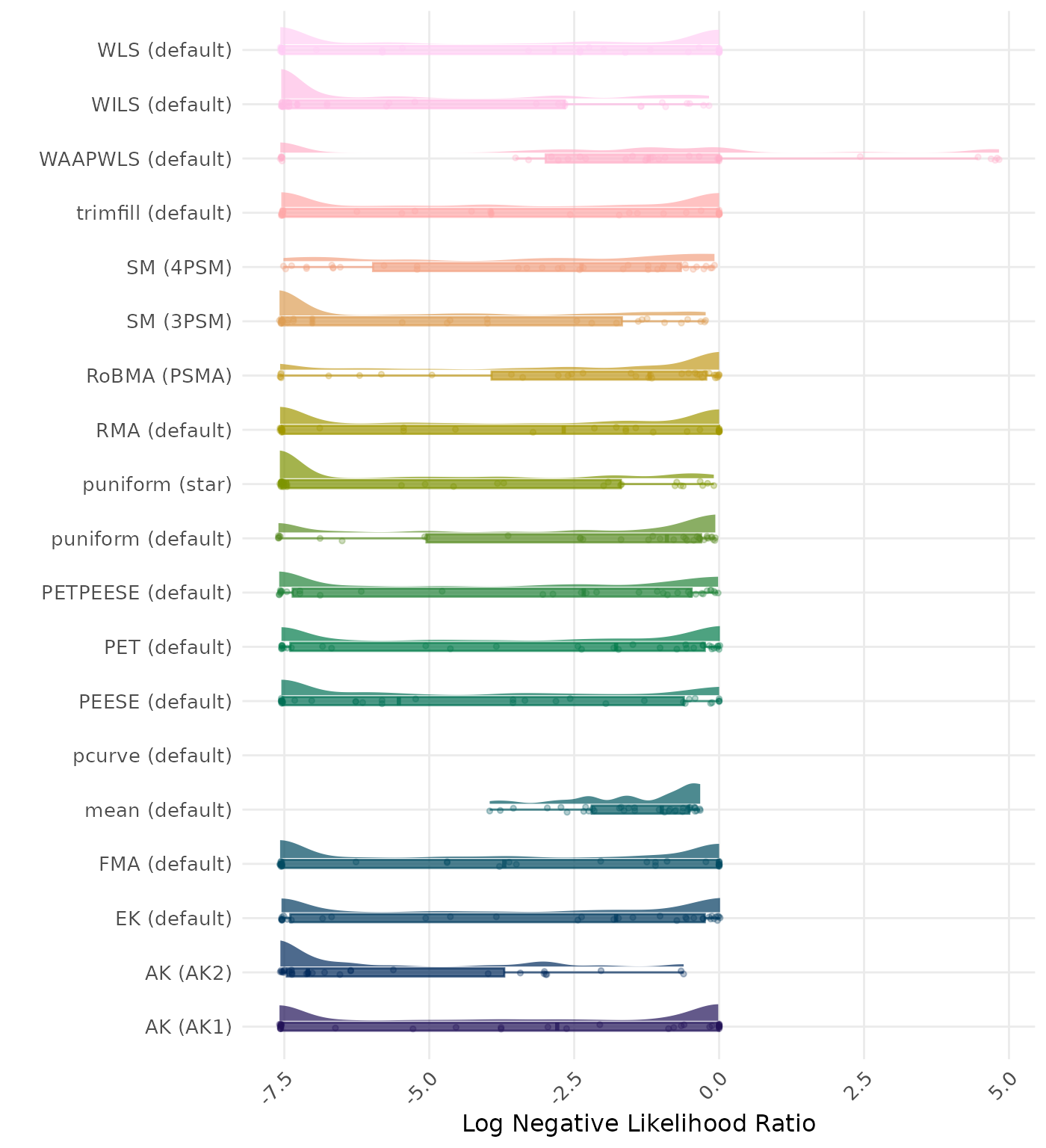
The negative likelihood ratio is an overall summary measure of hypothesis testing performance that combines power and type I error rate. It indicates how much a non-significant test result changes the odds of the alternative hypothesis versus the null hypothesis. A useful method has a negative likelihood ratio less than 1 (or a log negative likelihood ratio less than 0). A lower (log) negative likelihood ratio indicates a better method.
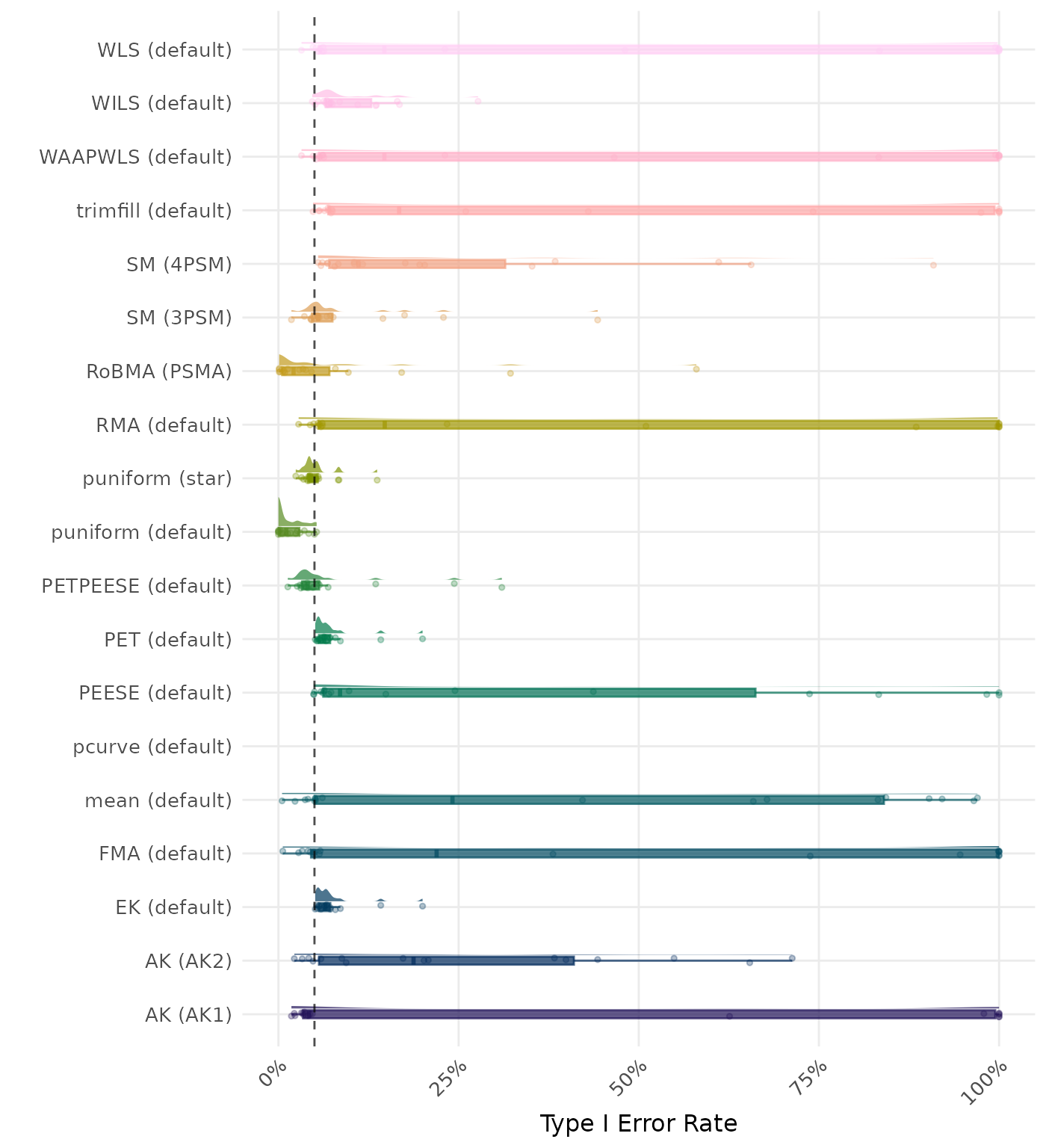
The type I error rate is the proportion of simulation runs in which the null hypothesis of no effect was incorrectly rejected when it was true. Ideally, this value should be close to the nominal level of 5%.
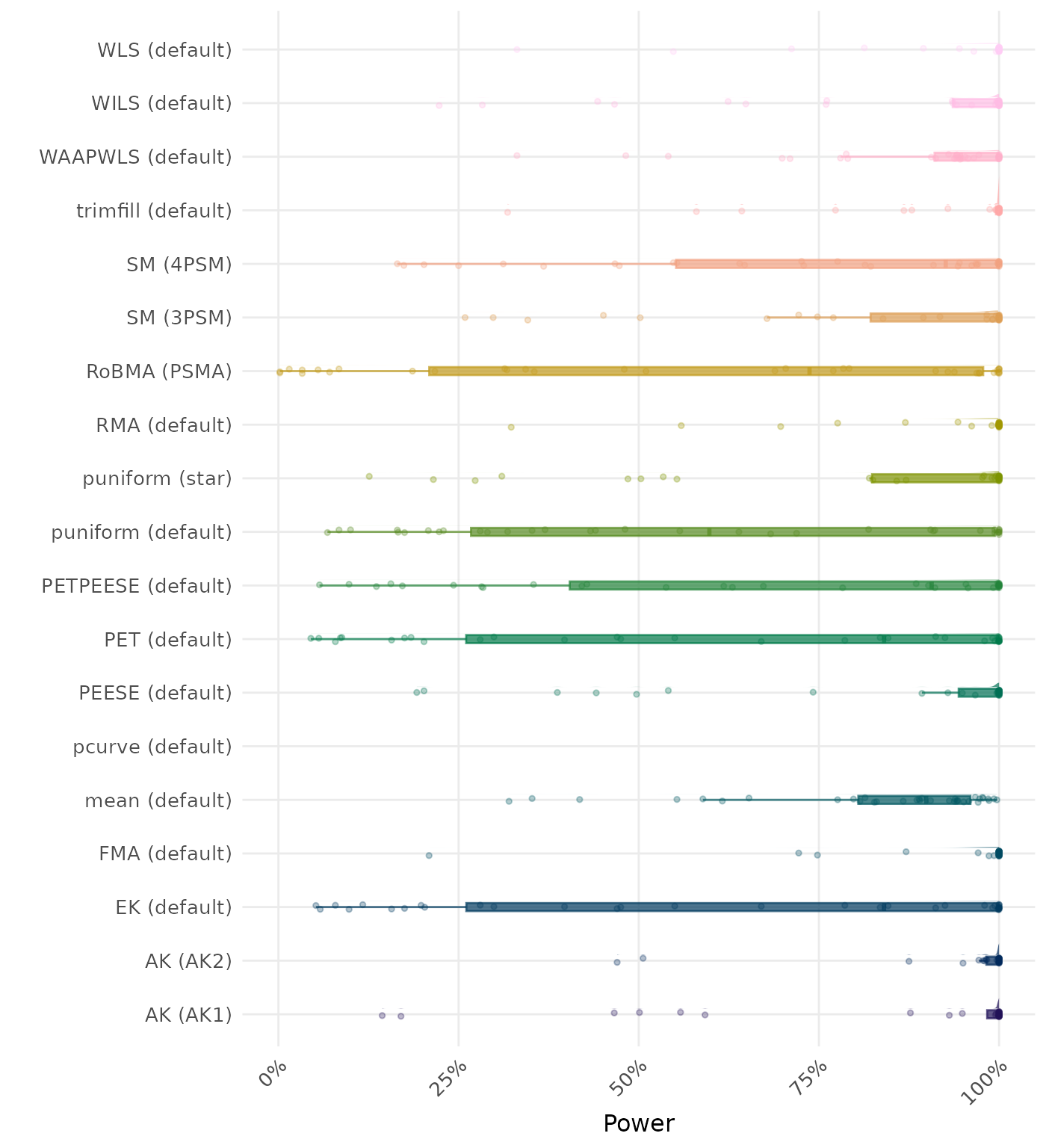
The power is the proportion of simulation runs in which the null hypothesis of no effect was correctly rejected when the alternative hypothesis was true. A higher power indicates a better method.
Session Info
This report was compiled on Sun May 24 10:17:58 2026 (UTC) using the following computational environment
## R version 4.6.0 (2026-04-24)
## Platform: x86_64-pc-linux-gnu
## Running under: Ubuntu 24.04.4 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
## LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
##
## locale:
## [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
## [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
## [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
## [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
##
## time zone: UTC
## tzcode source: system (glibc)
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] scales_1.4.0 ggdist_3.3.3
## [3] ggplot2_4.0.3 PublicationBiasBenchmark_0.2.1
##
## loaded via a namespace (and not attached):
## [1] generics_0.1.4 sandwich_3.1-1 sass_0.4.10
## [4] xml2_1.5.2 stringi_1.8.7 lattice_0.22-9
## [7] httpcode_0.3.0 digest_0.6.39 magrittr_2.0.5
## [10] evaluate_1.0.5 grid_4.6.0 RColorBrewer_1.1-3
## [13] fastmap_1.2.0 jsonlite_2.0.0 crul_1.6.0
## [16] urltools_1.7.3.1 httr_1.4.8 purrr_1.2.2
## [19] viridisLite_0.4.3 textshaping_1.0.5 jquerylib_0.1.4
## [22] Rdpack_2.6.6 cli_3.6.6 rlang_1.2.0
## [25] triebeard_0.4.1 rbibutils_2.4.1 withr_3.0.2
## [28] cachem_1.1.0 yaml_2.3.12 otel_0.2.0
## [31] tools_4.6.0 memoise_2.0.1 kableExtra_1.4.0
## [34] curl_7.1.0 vctrs_0.7.3 R6_2.6.1
## [37] clubSandwich_0.7.0 zoo_1.8-15 lifecycle_1.0.5
## [40] stringr_1.6.0 fs_2.1.0 htmlwidgets_1.6.4
## [43] ragg_1.5.2 pkgconfig_2.0.3 desc_1.4.3
## [46] osfr_0.2.9 pkgdown_2.2.0 bslib_0.11.0
## [49] pillar_1.11.1 gtable_0.3.6 Rcpp_1.1.1-1.1
## [52] glue_1.8.1 systemfonts_1.3.2 xfun_0.57
## [55] tibble_3.3.1 rstudioapi_0.18.0 knitr_1.51
## [58] farver_2.1.2 htmltools_0.5.9 labeling_0.4.3
## [61] svglite_2.2.2 rmarkdown_2.31 compiler_4.6.0
## [64] S7_0.2.2 distributional_0.7.0